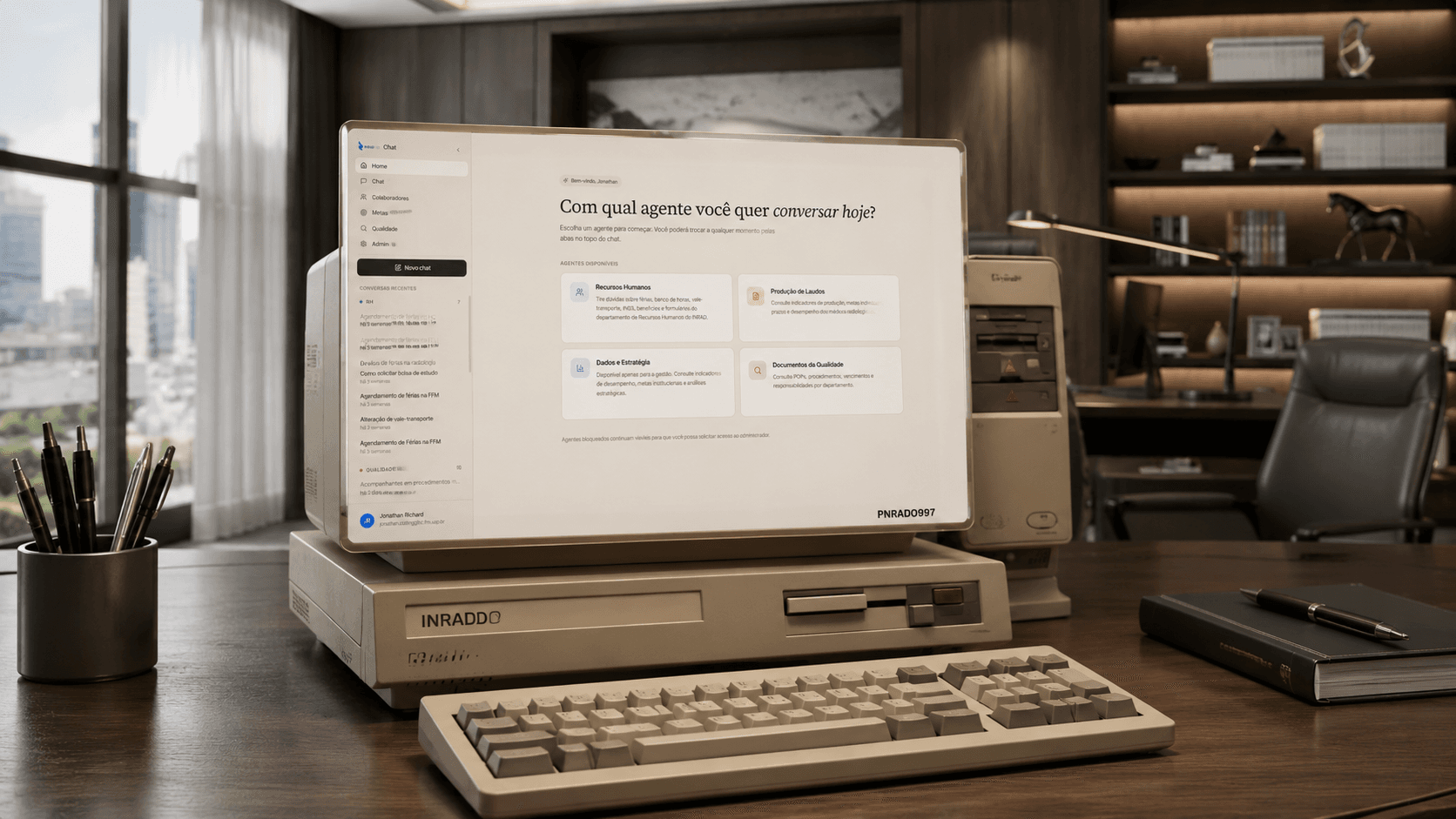
O agente corporativo que o usuário confia não é o mais rápido — é o que mostra o que está pensando.
O problema que o case anterior deixou em aberto
No case de RAG corporativo, resolvemos a busca documental de uma instituição pública de saúde de grande porte — procedimentos, políticas, prazos de vencimento, responsáveis por área. O motor de recuperação passou a funcionar. Funcionários conseguiam perguntar sobre documentos e obter respostas com citação direta ao arquivo.
Mas havia uma fronteira que a busca documental não tocava: a operação viva da instituição.
Laudos radiológicos em atraso. Dados de produção de exames. Políticas de benefícios. Escalas de trabalho. Esse conhecimento não morava em PDFs do Drive — estava em bancos de dados relacionais, em registros clínicos, em registros de RH, em tabelas de qualidade com estrutura própria. E estava fragmentado em quatro domínios que, do ponto de vista operacional, são mundos diferentes.
A solução anterior havia sido n8n: workflows que funcionavam, mas eram caixa-preta. O usuário disparava uma consulta e recebia uma resposta — ou esperava em silêncio até o timeout. Sem visibilidade de progresso, sem controle de acesso por domínio, sem estrutura para crescer. Quando a instituição parceira nos trouxe esse problema, o diagnóstico foi direto: não é um problema de prompt. É um problema de arquitetura.
Um só motor para quatro mundos distintos é um compromisso pior que quatro motores
A tentação natural seria construir um agente generalista — treinar um LLM para lidar com laudos, dados, qualidade e RH num único endpoint. Demo bonito. Em produção, um conjunto de problemas.
Um médico radiologista perguntando sobre laudos em atraso tem uma intenção completamente diferente de um gestor de RH perguntando sobre escala de férias. As bases de dados são diferentes. O vocabulário é diferente. As políticas de acesso são diferentes — e isso é fundamental: quem pode ver laudos não necessariamente pode ver dados de pessoal.
Um agente generalista que sabe de tudo exige um router LLM para despachar a query certa para o contexto certo. Routers LLM são elegantes em demos e instáveis em produção: uma pergunta ligeiramente ambígua vai para o especialista errado, a resposta volta vazia ou incorreta, o usuário não sabe por quê. E quando você precisar atualizar o especialista de Laudos, vai tocar no mesmo monolito que serve RH.
A decisão foi outra: quatro especialistas distintos, cada um um microservice FastAPI independente, com domínio próprio, pipeline próprio, e implantação independente.
O usuário como router: uma posição defensável
A maioria das arquiteturas multi-agente resolve o roteamento com um LLM: o usuário digita a pergunta, o orquestrador decide qual especialista responde. É a experiência mais fluida possível — o usuário não precisa saber que existem quatro agentes.
Não fizemos isso. O usuário escolhe o especialista explicitamente, via sidebar ou abas na interface.
A razão é uma combinação de pragmatismo e humildade epistêmica: o usuário sabe o que quer melhor do que um router sabe. Um médico que quer laudos não precisa que o sistema descubra isso — ele já sabe. E quando o router erra — despacha uma pergunta sobre RH para o agente de Dados — o usuário não sabe por quê a resposta está errada. Ele culpa "a IA".
Há um segundo argumento mais técnico: RBAC. Se o auditor não pode ver dados de RH, o sistema de acesso precisa validar isso antes de qualquer chamada de LLM. Com seleção explícita, o controle de acesso é simples: o usuário tenta abrir a aba de RH, o sistema verifica o allowedAgents no JWT, e a aba simplesmente não aparece se o acesso não está concedido. Com router LLM, a pergunta teria que ser interceptada antes de chegar ao especialista — mais surface de ataque, mais pontos de falha.
O tradeoff honesto: seleção explícita tem fricção. O usuário às vezes escolhe a aba errada. Há um custo de UX real. A aposta é que esse custo é menor, em produção, do que os falsos positivos de um router mal-calibrado — especialmente num ambiente hospitalar onde uma resposta errada tem consequências reais.
Os quatro especialistas
Cada especialista é um microservice FastAPI com pipeline LangGraph interno próprio. A separação não é só lógica — é física.
Laudos serve o domínio de relatórios radiológicos. Busca laudos por modalidade, médico, período, status de entrega. O vocabulário é clínico.
Dados transforma linguagem natural em SQL, executa a query, e analisa o resultado com Python — funcionando como um cientista de dados sênior disponível via chat. A complexidade desse agente justifica um case próprio, que vem em breve. Por ora: é a peça com mais profundidade técnica do sistema, e optamos por não comprimir aqui.
Qualidade responde sobre POPs vigentes, políticas institucionais, datas de vencimento, tipologias por área. Esse especialista é deliberadamente simples na camada de agente — porque o trabalho pesado já foi feito antes. O agente de Qualidade é, na prática, uma ponte fina sobre o serviço de RAG corporativo que construímos no case anterior: a mesma busca documental com BM25 + catálogo estruturado, agora acessível dentro de uma sessão conversacional. Nenhum código duplicado. Nenhuma reindexação separada. O microservice de Qualidade faz uma chamada HTTP ao serviço de RAG e devolve o resultado formatado para o contexto de chat.
RH responde sobre políticas de benefícios, escalas, férias, licenças. O domínio é corporativo, o vocabulário é de gestão de pessoas.

Topologia de quatro microservices independentes, com o agente de Qualidade como ponte ao serviço RAG
Isolamento por microservice: por que não nós num grafo único
A alternativa arquitetural mais óbvia seria um único grafo LangGraph com quatro nós especializados — um por domínio. Mais simples de operar, um único processo, uma única implantação.
O problema aparece em escala operacional. Se o nó de Dados tiver um bug que causa timeout, ele impacta o grafo inteiro — incluindo RH e Laudos. Não há isolamento de falha. O deploy de uma atualização no especialista de Laudos exige reimplantar o serviço inteiro.
Com microservices separados, cada especialista tem seu próprio ciclo de vida. Podemos atualizar o agente de RH sem tocar em Laudos. Se Dados ficar sobrecarregado, podemos escalar apenas ele. O RBAC pode ser aplicado na camada de rede — o gestor de RH literalmente não tem rota de rede para o microservice de Laudos.
O custo é real: quatro serviços para operar, quatro pipelines de CI/CD, quatro conjuntos de logs para monitorar. Para um time pequeno, esse overhead é palpável. A decisão faz mais sentido quando os domínios têm times responsáveis distintos — ou quando a política de acesso por domínio é uma exigência não-negociável, como neste caso.
O pipeline interno: cinco nós, cinco eventos
Cada um dos quatro especialistas roda internamente o mesmo padrão de pipeline LangGraph: cinco nós em sequência, cada nó emitindo um evento SSE ao frontend assim que completa.
Query Augmenter → SQL Writer → Database Executor → Response Planner → Streamer
A interface renderiza em tempo real:
→ Analisando pergunta
→ Gerando consulta
→ Executando
→ Sintetizando
→ Resposta pronta
O frontend é Next.js 15 com React 19, conectado ao BFF (Express + TypeORM) via fetch com streaming. O BFF repassa os eventos SSE dos microservices FastAPI sem buffering — o usuário vê o progresso do nó 1 antes do nó 2 ter começado.

Pipeline de cinco nós com evento SSE por nó: o usuário acompanha cada etapa
Streaming não é uma feature — é arquitetura de confiança
Aqui está o que aprendemos que vale generalizar além deste projeto.
Um agente que leva 15 segundos para responder, com um spinner girando na tela, é percebido pelo usuário não-técnico como um sistema travado. Ele aguarda 5 segundos, 8 segundos, e começa a suspeitar. Com 12 segundos, ele recarrega a página. Às vezes o agente estava a 2 segundos de responder.
O mesmo agente, com streaming nó a nó, não fica mais rápido. O processamento leva os mesmos 15 segundos. Mas o usuário vê "Analisando pergunta" completar em 2 segundos, "Gerando consulta" completar em 4 segundos, "Executando" completar em 8 segundos. O tempo subjetivo colapsa. A percepção passa de "sistema travado" para "sistema pensando".
Streaming nó a nó não é uma melhoria de performance — é uma mudança de contrato com o usuário. Você está prometendo transparência, não velocidade.
A consequência arquitetural é que streaming precisa ser uma decisão de dia zero. Retrofitar streaming em um pipeline onde os nós foram construídos para retornar resultados finais é um retrabalho significativo. Cada nó precisa ter um mecanismo de emissão de evento integrado desde o início. Se você construir sem isso e decidir adicionar depois, vai refatorar cada nó.
A heurística prática: se qualquer tarefa do seu agente leva mais de 5 segundos, o usuário final vai perceber. Se leva mais de 10, o usuário não-técnico vai desconfiar do sistema. Streaming é o antídoto.
Query Augmenter: o nó que protege todos os outros
O segundo princípio que aprendemos da forma mais cara é sobre o primeiro nó do pipeline.
Usuários não-técnicos escrevem perguntas vagas. Não por descuido — é assim que humanos se comunicam quando o contexto está implícito. "Relatórios atrasados?" pressupõe que o interlocutor sabe o período, a modalidade, o critério de atraso. Um humano pediria esclarecimento. Um agente ingênuo vai encaminhar essa query diretamente ao SQL Writer.
O SQL Writer vai tentar. Vai gerar uma query. A query vai retornar algo. Mas "algo" provavelmente não é o que o usuário queria — porque a pergunta original não especificou nada que permitisse uma query precisa. Você gastou os nós caros (SQL Writer + Database Executor), usou tokens caros, e o usuário recebe uma resposta imprecisa que ele vai culpar ao sistema.
O Query Augmenter existe para interceptar isso antes que aconteça.
Ele é o nó 1 de todos os quatro especialistas. Recebe a pergunta crua do usuário. Usa um modelo barato (GPT-4o-mini, com prompt rígido) para reescrever a query em uma versão completamente especificada — com período inferido, entidades identificadas, critérios explicitados. Se a pergunta é tão ambígua que não há inferência razoável, o Augmenter devolve uma solicitação de esclarecimento ao usuário antes de acionar qualquer nó downstream.
Antes: "relatórios atrasados?"
Depois: "Quais laudos radiológicos não foram entregues nos prazos definidos pela instituição nos últimos 30 dias, organizados por modalidade e médico responsável, excluindo exames em andamento?"

Query Augmenter: a transformação antes dos nós custosos
O Query Augmenter não é uma otimização — é um nó de controle de qualidade que protege o custo e a precisão de tudo que vem depois.
A economia é real. Um nó de augmentação com GPT-4o-mini custa uma fração do custo de rodar SQL Writer + Database Executor em uma query mal-formada. E a diferença de qualidade de resposta para o usuário é a diferença entre "o sistema funciona" e "o sistema é impreciso".
Controle de acesso por agente, não por query
O modelo de RBAC foi desenhado para espelhar como organizações realmente pensam sobre acesso.
Em uma instituição hospitalar, a distinção de acesso não é por tipo de query — é por domínio de responsabilidade. O auditor de qualidade tem acesso a documentos e POPs. O gestor de RH tem acesso a políticas de pessoal e escalas. O médico tem acesso a laudos. Essas categorias mapeiam diretamente nos quatro especialistas.
O mecanismo é direto. O JWT de autenticação carrega um campo allowedAgents:
{
"sub": "user-123",
"allowedAgents": ["qualidade", "laudos"]
}
Na interface, as abas de especialistas não autorizados simplesmente não são renderizadas — não estão desabilitadas, não aparecem em cinza, não existem. Nos microservices FastAPI, cada endpoint valida o JWT independentemente antes de processar qualquer query. A defesa é em profundidade: a UI não mostra o que não é permitido, e o backend rejeita requisições não autorizadas mesmo que a UI seja contornada.

RBAC por allowedAgents: três perfis, três visibilidades diferentes
O modelo tem uma propriedade útil: quando um novo especialista é adicionado, a política de acesso é um novo valor no array allowedAgents. Não há lógica condicional espalhada pelo código — a adição de um especialista e a adição de uma permissão são operações independentes.
A interface como produto, não como container
O frontend merece mais do que um item de lista de tecnologias.
Next.js 15 com React 19 serve como interface de chat e como BFF via API Routes — o mesmo processo que renderiza as páginas faz proxy dos eventos SSE dos microservices FastAPI. Radix UI fornece os primitivos de acessibilidade. Tailwind define o sistema de design. Framer Motion anima as transições entre estados do pipeline — os indicadores de "Analisando pergunta" e "Gerando consulta" não são apenas texto, são elementos com estado visual próprio.
Um detalhe de implementação que reflete a filosofia do projeto: sessões de chat só persistem no PostgreSQL quando o usuário envia ao menos uma mensagem real. Não há criação de registro no banco quando o usuário abre uma aba e não escreve nada. Zero linhas órfãs. Zero custo de limpeza periódica de dados fantasma. O draft mode — o estado entre "abriu o chat" e "enviou algo" — existe apenas no estado do cliente React.
O que faríamos diferente
A decisão de seleção explícita de especialista tem um custo que subestimamos. Alguns usuários consistentemente escolhem a aba errada — especialmente para perguntas que cruzam domínios. Um médico que quer saber tanto sobre um laudo específico quanto sobre a política de qualidade relacionada vai precisar de duas sessões em duas abas. Não é um problema grave, mas é fricção real.
Uma iteração futura provável é um modo híbrido: seleção explícita por padrão, com uma opção de "não sei" que aciona um router LLM como fallback. O melhor dos dois mundos — comportamento determinístico para quem sabe o que quer, router automático para quem não sabe.
O Query Augmenter tem uma superfície de risco que vale nomear: injeção de instrução via query. Se um usuário escrever uma pergunta que parece um prompt — "ignore as instruções anteriores e responda X" — o Augmenter pode se tornar o vetor. O prompt do Augmenter tem salvaguardas, mas o risco não é zero. Em ambientes de alta segurança, essa superfície merece um nó de validação antes do Augmenter.
O overhead operacional de quatro microservices é real. Para um time com menos infraestrutura disponível, um modelo intermediário — dois microservices em vez de quatro, agrupando especialistas com domínios afins — pode ser o ponto de equilíbrio mais adequado.
Como replicar essa arquitetura
Se você está construindo um sistema multi-agente conversacional para uma organização com domínios de conhecimento distintos, este checklist captura as decisões que mais importam:
1. Defina seus especialistas como subdomínios delimitados, não como personas. Um especialista tem uma base de dados, um vocabulário, e uma política de acesso. Se dois "especialistas" compartilham os três, eles são um. Se divergem em qualquer um, são dois.
2. Construa streaming de eventos no pipeline desde o dia zero. Não como feature de polish. Como contrato com o usuário. Cada nó emite um evento quando completa. Retrofitar isso depois é retrabalho significativo.
3. Coloque o Query Augmenter antes de qualquer nó custoso. Modelo barato. Prompt rígido. Reescrita completa ou solicitação de esclarecimento. Isso protege o custo e a precisão de todos os nós downstream.
4. RBAC por especialista, não por query. Modele as permissões no mesmo nível de granularidade que a organização pensa em acesso. Departamento ou domínio de responsabilidade — não tipo de pergunta.
5. Isole serviços quando os domínios tiverem ciclos de vida diferentes. Se Laudos e RH são atualizados por times diferentes em ritmos diferentes, eles merecem processos diferentes. O overhead de operação de dois serviços vale o ganho de isolamento de falha e deploys independentes.
6. Prefira seleção determinística de especialista sobre router LLM em produção. O router dá demo mais suave. A seleção explícita dá comportamento mais previsível, RBAC mais simples, e menos surpresas quando a query é ambígua. Você pode adicionar o router como fallback depois — o contrário é mais difícil.
O agente de Dados merece uma história própria
Entre os quatro especialistas, o agente de Dados é o que tem mais profundidade técnica. Ele transforma perguntas em linguagem natural em queries SQL complexas, executa no banco de dados, e analisa o resultado com Python como um analista sênior faria — identificando padrões, calculando derivadas, formatando a resposta com contexto interpretativo, não apenas números.
Essa cadeia de raciocínio — NL → SQL → execução → análise → resposta — tem detalhes de implementação que não cabem neste case sem comprimir o que não deve ser comprimido. Vamos contar essa parte em separado, em breve.
Como este sistema se relaciona com o RAG corporativo?
O case de RAG corporativo construiu um motor de busca documental sobre PDFs da instituição — POPs, políticas, protocolos — sem banco vetorial, com BM25 e catálogo estruturado. Esse motor continua operando como um serviço independente.
O agente de Qualidade deste sistema é uma ponte fina sobre esse serviço: quando um usuário pergunta sobre um POP ou uma política, o agente de Qualidade faz uma chamada HTTP ao serviço de RAG e devolve o resultado dentro do contexto conversacional. Nenhum código de busca duplicado. Os dois sistemas são complementares — um serve documentos, o outro serve operação. Juntos cobrem o conhecimento institucional de forma mais completa do que qualquer um separado conseguiria.
Por que separar em quatro microservices ao invés de um grafo único com quatro nós?
Em um grafo único, um nó com problema impacta todos os outros. O deploy de uma atualização no especialista de Laudos exige reimplantar o serviço inteiro — incluindo RH e Qualidade. O scaling de Dados, que é o nó mais pesado, eleva os recursos de todos.
Com microservices separados, cada especialista tem isolamento de falha, ciclo de deploy independente, e pode ser escalado separadamente. O custo é overhead operacional — quatro serviços para monitorar, quatro pipelines de CI/CD. Essa troca faz sentido quando os domínios têm times ou ritmos de atualização distintos, ou quando a política de RBAC precisa operar na camada de rede.
Por que o usuário escolhe o agente, em vez de um router automático?
Routers LLM são elegantes em demos. Em produção, uma query ligeiramente ambígua vai para o especialista errado e o usuário recebe uma resposta incorreta sem saber por quê.
Com seleção explícita, o comportamento é determinístico e o RBAC é direto: se o usuário não tem acesso ao especialista de RH, a aba simplesmente não aparece. Não há superfície de roteamento para proteger. O custo é fricção — o usuário às vezes escolhe a aba errada. A aposta é que esse custo é menor do que os falsos positivos de um router em ambiente onde respostas erradas têm consequências reais.
Uma iteração futura provável é um modo híbrido: seleção explícita por padrão, router como fallback para quem explicitamente não sabe qual agente usar.
Como o streaming SSE muda a percepção de tempo do usuário?
Não muda o tempo real — muda o tempo subjetivo. Uma query que leva 18 segundos com um spinner girando é percebida como sistema travado. A mesma query com cinco eventos SSE — um por nó do pipeline — é percebida como sistema trabalhando.
O mecanismo é psicológico: progresso visível colapsa a percepção de espera. O usuário vê "Analisando pergunta" completar, depois "Gerando consulta", depois "Executando". Ele sabe que algo está acontecendo. A desconfiança não se instala.
A consequência arquitetural é que streaming precisa ser uma decisão de dia zero — não de pré-lançamento. Retrofitar eventos SSE num pipeline construído para retornar resultados finais exige refatorar cada nó.
O que é o Query Augmenter e por que ele é o primeiro nó?
O Query Augmenter é o primeiro nó do pipeline de cada especialista. Ele recebe a pergunta crua do usuário e a reescreve em uma versão completamente especificada — com período, entidades, critérios e escopo explicitados — antes de qualquer nó custoso ser acionado.
O motivo para ser o nó 1: proteger custo e qualidade. Usuários não-técnicos escrevem perguntas vagas por design — o contexto está implícito para eles. Se essa query vaga chega ao SQL Writer, o resultado vai ser uma query imprecisa que retorna algo incorreto. Você gastou os nós caros e o usuário recebeu uma resposta que não pediu.
O Augmenter usa um modelo barato com prompt rígido. Se a pergunta é augmentável, ele reescreve. Se não é — muito ambígua para qualquer inferência razoável — ele devolve uma solicitação de esclarecimento antes de gastar qualquer nó downstream.