Em instituições de alta complexidade, o conhecimento já está documentado. O problema é que ninguém sabe onde ele está — e quando vencem os prazos.
O setor de qualidade como central de suporte involuntária
Uma instituição pública de saúde de grande porte — centenas de funcionários distribuídos entre setores clínicos, administrativos e técnicos — mantém um corpus vivo de documentos internos. Procedimentos Operacionais Padrão, políticas institucionais, planos de contingência, manuais técnicos, protocolos, instruções de trabalho. O conjunto inteiro existia, estava escrito, passava por revisão periódica, tinha responsável e data de vencimento. Nada disso era novidade.
O que era novidade era o volume de chamados chegando ao setor de qualidade toda semana: "onde está esse documento?", "qual é a versão atual do protocolo de X?", "o POP de identificação de paciente ainda é válido?". Perguntas que tinham resposta no Drive — às vezes numa pasta a dois cliques de distância. A equipe de qualidade virou, por osmose, a interface de busca humana para um acervo que ninguém sabia navegar.
Esse é o custo invisível de uma base de conhecimento sem motor de recuperação: não é que o conhecimento esteja errado. É que ele está inacessível em escala operacional.
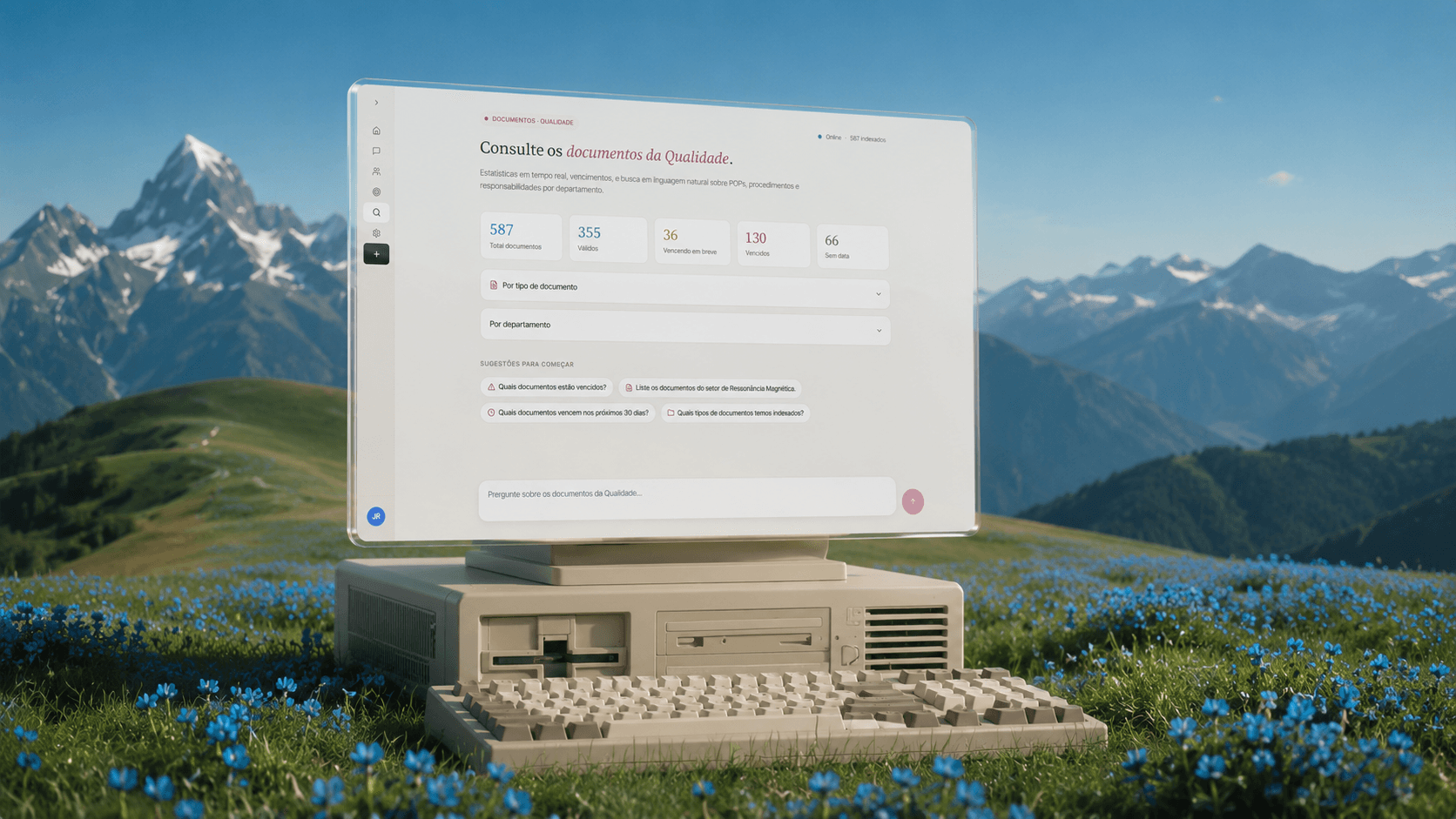
O cliente nos trouxe o problema em termos diretos: os funcionários precisam conseguir perguntar ao sistema e receber resposta. Sem depender de uma pessoa-chave. Sem abrir pastas no Drive e contar com sorte.
A tentação do RAG textbook — e por que pausamos
A arquitetura canônica de RAG (Retrieval-Augmented Generation) para esse cenário seria óbvia: indexar os PDFs num banco vetorial, gerar embeddings de cada chunk, buscar por similaridade semântica na query, passar os chunks relevantes ao LLM, devolver resposta. É o fluxo que a maioria dos tutoriais mostra. É também o fluxo que, nesse caso específico, teria criado dois problemas sérios logo de cara.
Primeiro crack: embeddings não respondem perguntas de governança
Busca semântica é ótima para "o que este documento diz sobre identificação de paciente". Ela é inútil para "quais documentos vencem nos próximos 30 dias" ou "quais procedimentos estão sob responsabilidade do gestor da área de qualidade".
Essas últimas não são perguntas de conteúdo. São perguntas de metadados. A resposta não está no corpo de nenhum documento — está no campo next_review_date do cabeçalho e no campo responsible do rodapé. Um banco vetorial não indexa esses campos de forma consultável. Para essa classe de query, embeddings simplesmente não são o mecanismo certo.
E essa classe de query importa muito para gestão de conformidade. Saber o que vence, saber o que está defasado, saber quem é responsável pelo quê — são exatamente as perguntas que um auditor faz. Se o sistema não consegue responder, metade do valor de negócio some.

A mesma pergunta em dois índices: um semântico, um estruturado
Segundo crack: reindexação contínua como imposto operacional
Corpora ativos mudam. POPs são revisados. Novos protocolos entram. Versões antigas são arquivadas. Num banco vetorial, qualquer mudança no documento exige rechunking e re-embedding do arquivo inteiro — e, dependendo da implementação, eventual reindexação do ANN (Approximate Nearest Neighbor) inteiro.
Para um corpus de 600 documentos com atualização frequente, esse ciclo vira um overhead operacional significativo. Não é intratável, mas é uma dívida técnica real: custo de API para embeddings, latência de sincronização, risco de índice desatualizado durante a janela de reindexação.
Todo projeto de aplicação de IA na prática exige uma camada de observação do processo no formato que ele é hoje. Antes de escrever uma linha de código, olhar para o que existe.
O que a observação revelou: os títulos já são o índice
Antes de escolher a arquitetura, passamos tempo olhando para o corpus como ele era. Não como queríamos que fosse — como era.
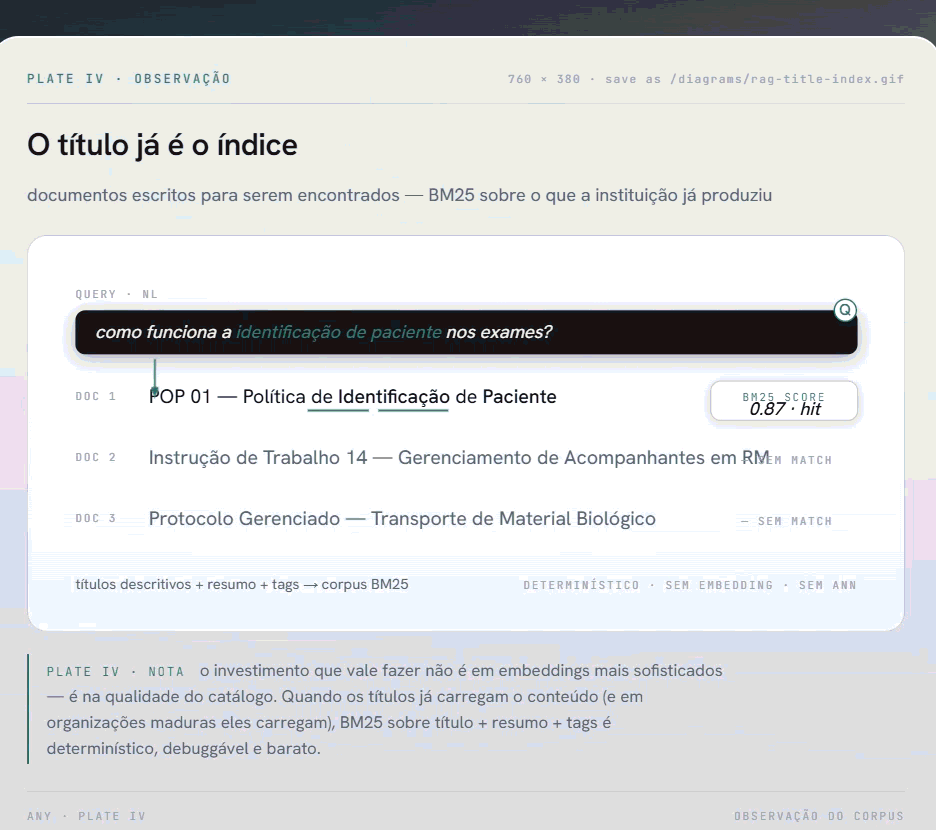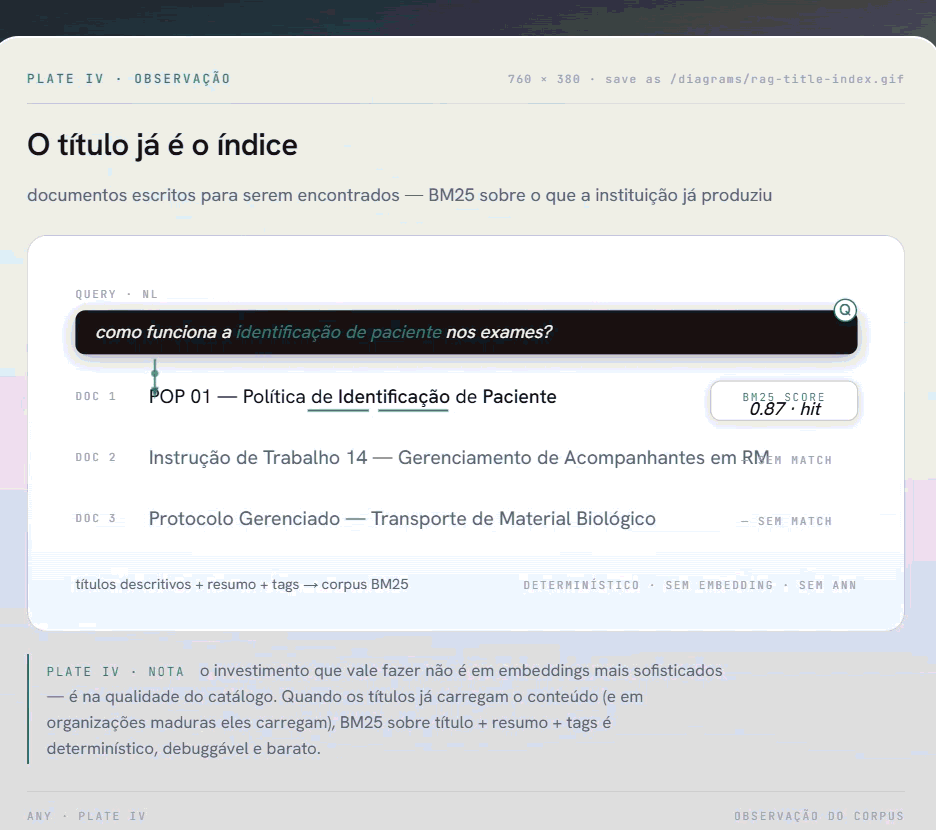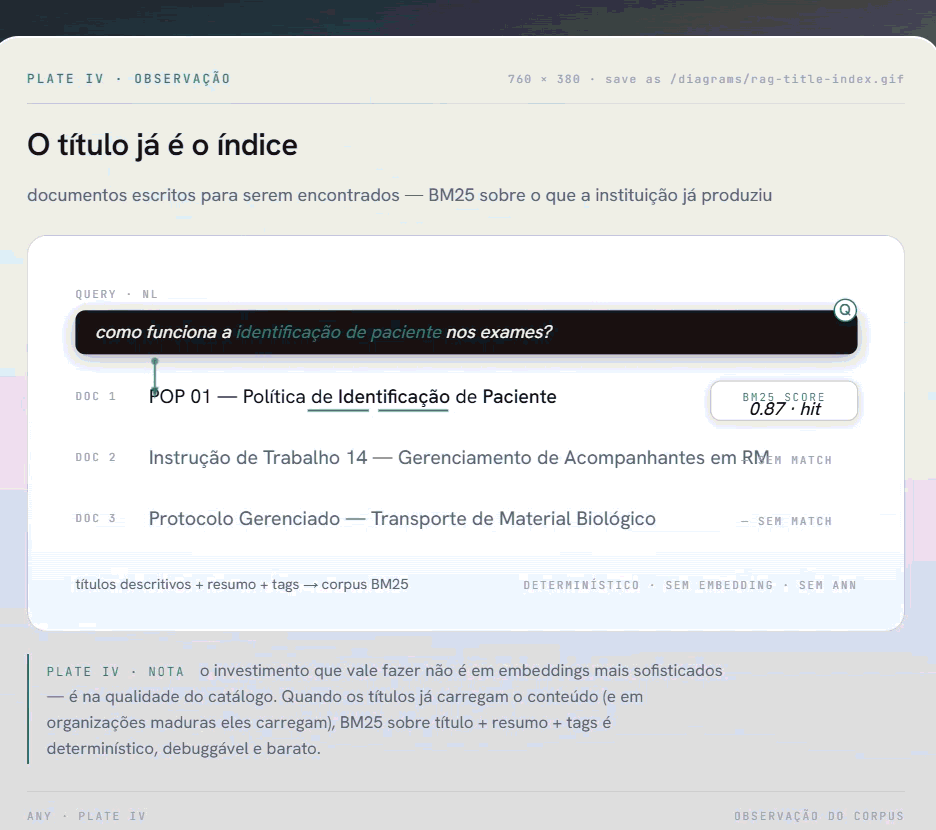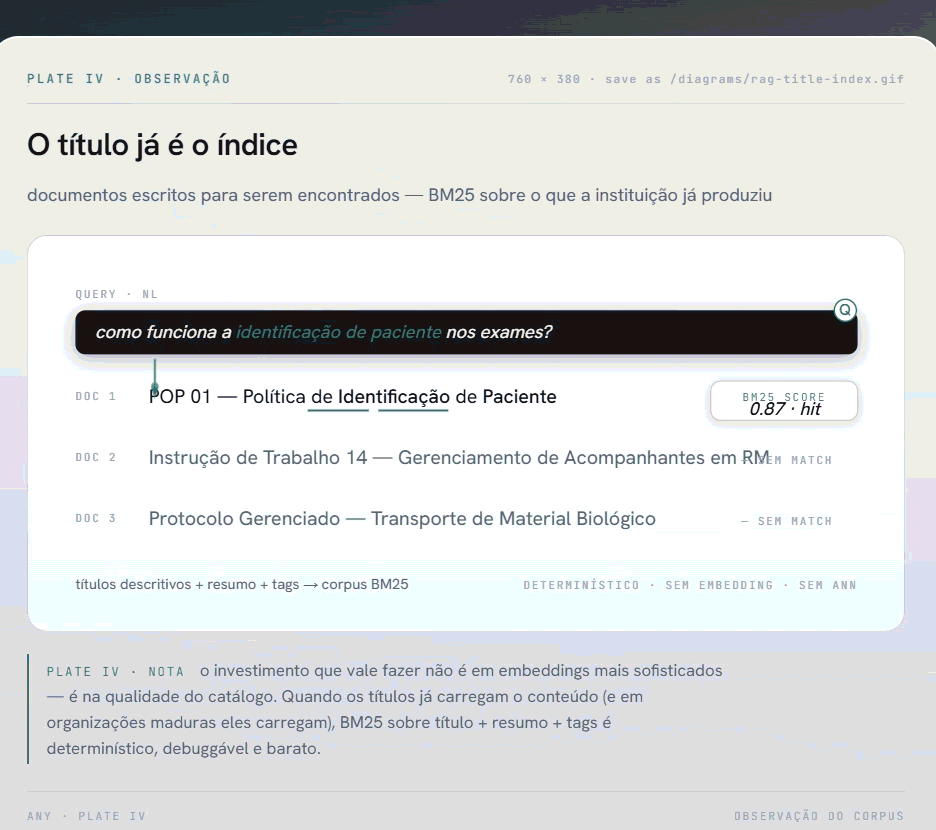
A descoberta foi direta: os documentos dessa instituição tinham sido escritos para serem encontrados. Os títulos eram descritivos por convenção institucional. "POP 01 - Política de Identificação de Paciente". "Instrução de Trabalho 14 - Gerenciamento de Acompanhantes em Procedimentos de RM". Cada título funcionava como um resumo do conteúdo.
Se um funcionário pergunta sobre identificação de paciente, o título já sinaliza o documento relevante. Não precisamos de um vetor de 1536 dimensões para perceber isso. Precisamos de uma busca léxica decente sobre o título, reforçada com um resumo gerado uma única vez no momento da indexação.
A lógica da decisão ficou clara: o investimento que valeria fazer era na qualidade do catálogo, não na infra de embeddings.
Os títulos já são o índice: BM25 sobre o catálogo dispensa embeddings
A decisão arquitetural: catálogo como dimensão filtrável, BM25 como motor de busca
Descartamos o banco vetorial. No lugar, construímos um catálogo estruturado em JSONL — uma entrada por documento — com os seguintes campos extraídos no momento da indexação:
title,doc_type,department— identidade e taxonomiasummary,tags,entities— gerados por LLM (GPT-4o-mini, por ser 10× mais barato que Sonnet para tarefas de indexação em batch)next_review_date,last_review_date,issue_date,version— extraídos via regex no cabeçalhoresponsible,approver— extraídos via regex no rodapé, com fallback para LLM quando o regex falha
Cada documento é lido uma única vez na indexação. O texto extraído fica em cache local. Reindexar um documento atualizado é reprocessar uma entrada JSONL — não é recalcular um embedding e atualizar um índice ANN.
A busca usa rank-bm25 sobre o corpus de textos BM25 construído a partir de título + resumo + tags. BM25 é determinístico: a mesma query retorna o mesmo ranking toda vez. É debuggável. E para corpus com vocabulário controlado (terminologia clínica e institucional consistente), ele performa bem.
A taxonomia que não pode alucinar
O campo doc_type — se um documento é um POP, uma política, um protocolo gerenciado, uma instrução de trabalho — vem da pasta onde o arquivo está no Drive. Não do LLM.
TAXONOMY_PREFIXES = {
"pop": ["POP"],
"politica": ["POLÍTICA INTERNA"],
"plano_contingencia": ["PLANO DE CONTINGÊNCIA"],
"instrucao_trabalho": ["INSTRUÇÃO DE TRABALHO"],
"protocolo_gerenciado": ["PROTOCOLO GERENCIADO"],
"protocolo_tecnico": ["PROTOCOLO TÉCNICO"],
"manual": ["MANUAL"],
"tutorial": ["TUTORIAL"],
"programa_interno": ["PROGRAMAS"],
"cartilha": ["CARTILHAS INFORMATIVAS"],
"documento_corporativo": ["DOCUMENTOS CORPORATIVOS"],
}
A ordem importa: protocolo_gerenciado precisa ser testado antes de protocolo, senão o prefixo genérico captura tudo. O match é por prefixo com normalização de case e acentos. PDFs em pastas fora da taxonomia são silenciosamente descartados — comportamento intencional para manter o índice limpo.
Resultado: é impossível o sistema classificar um POP como manual. O tipo vem da estrutura de pastas, que os gestores de qualidade já mantêm. Não há alucinação possível num campo derivado deterministicamente do filesystem.
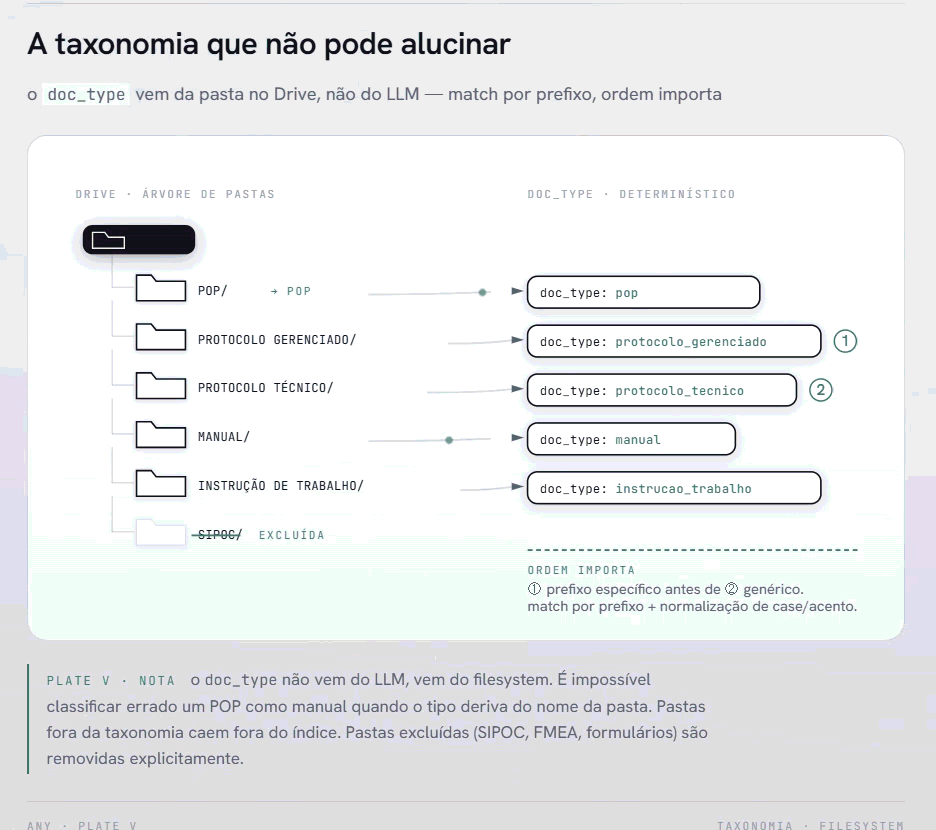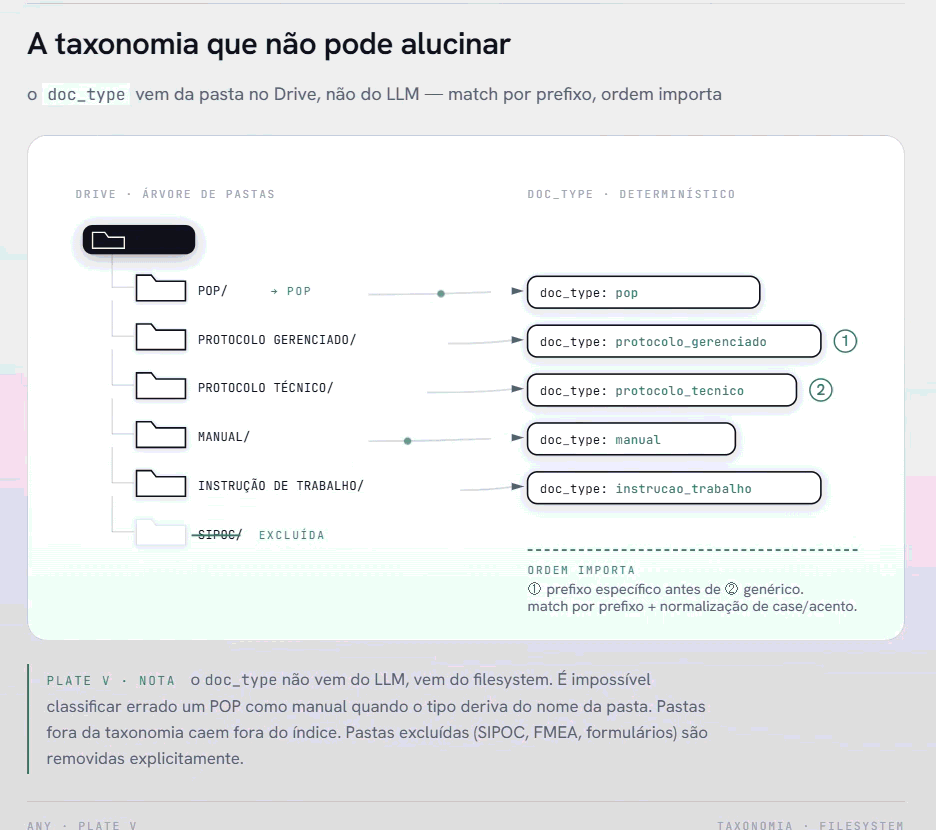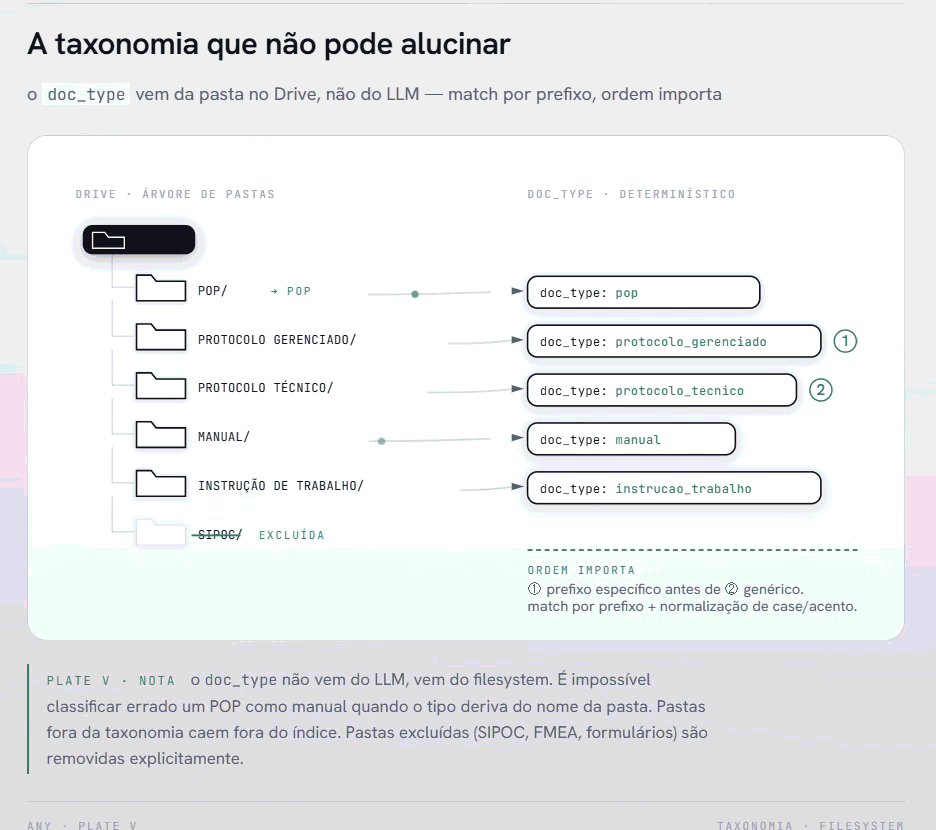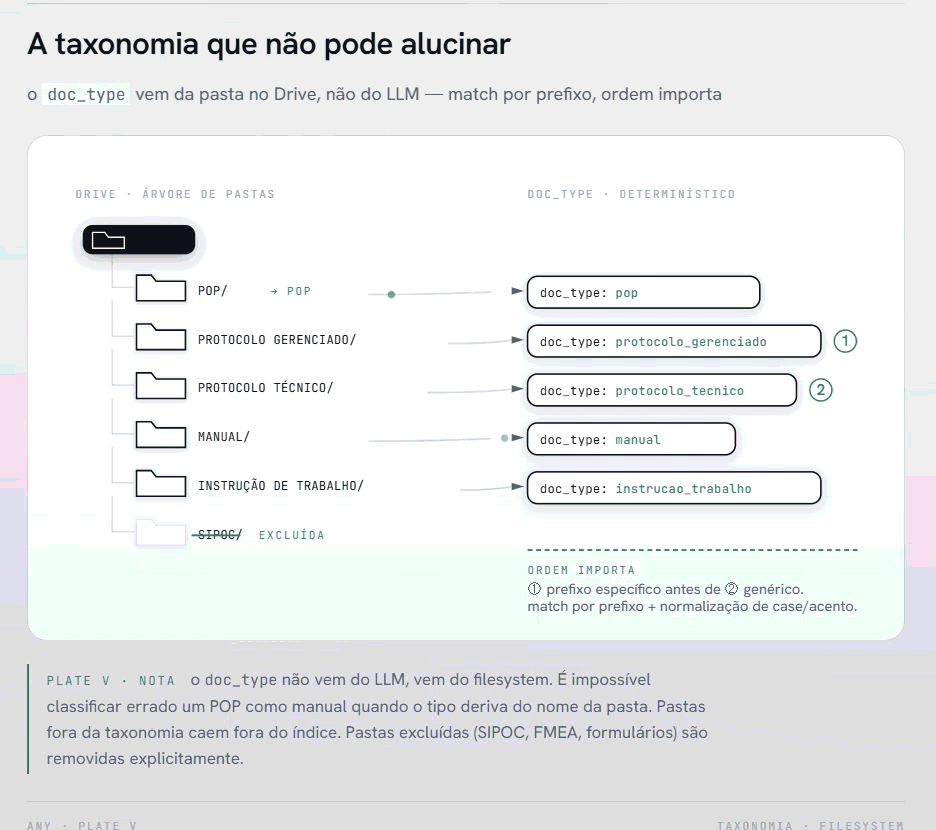
A taxonomia que não pode alucinar: o doc_type deriva da estrutura de pastas
A arquitetura MapReduce agentica
O problema de janela de contexto em RAG é real. Se recuperarmos 10 documentos completos e os enviarmos a um LLM, estamos falando de ~50.000 tokens. A qualidade da resposta cai. O custo sobe. E o orquestrador perde capacidade de raciocínio para a síntese porque o contexto está entupido de texto bruto.
O padrão que adotamos replica a lógica de sistemas como o Perplexity e o Deep Research da OpenAI: um orquestrador que nunca lê documentos completos, mais N sub-agentes descartáveis que leem um documento cada e devolvem apenas a extração relevante.
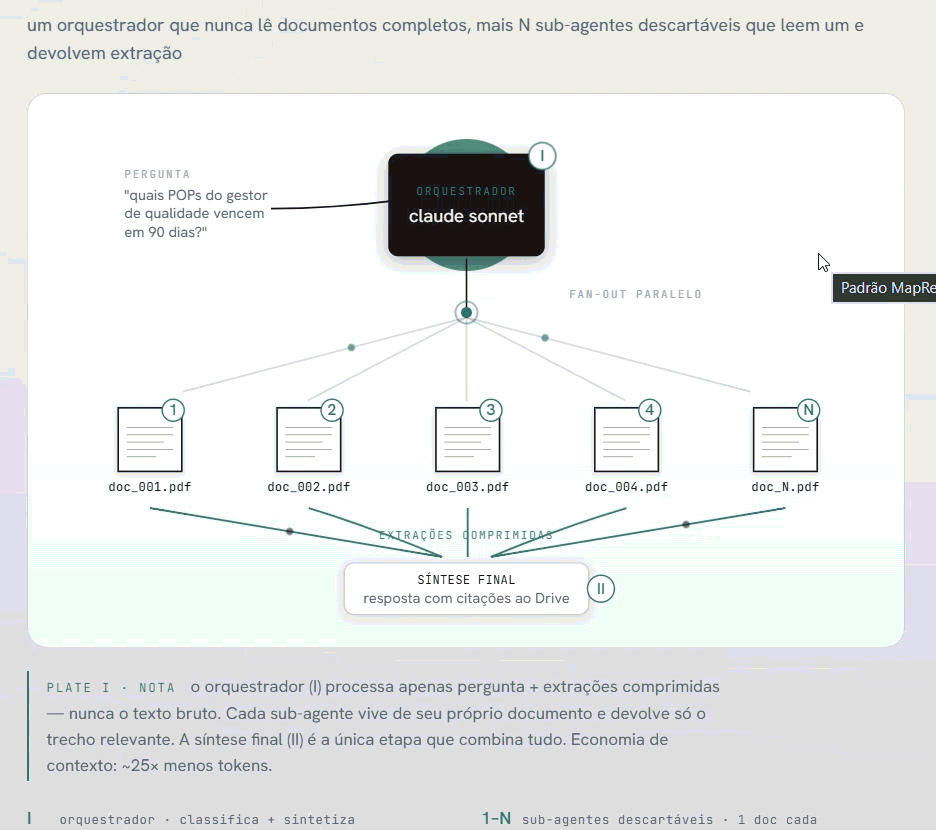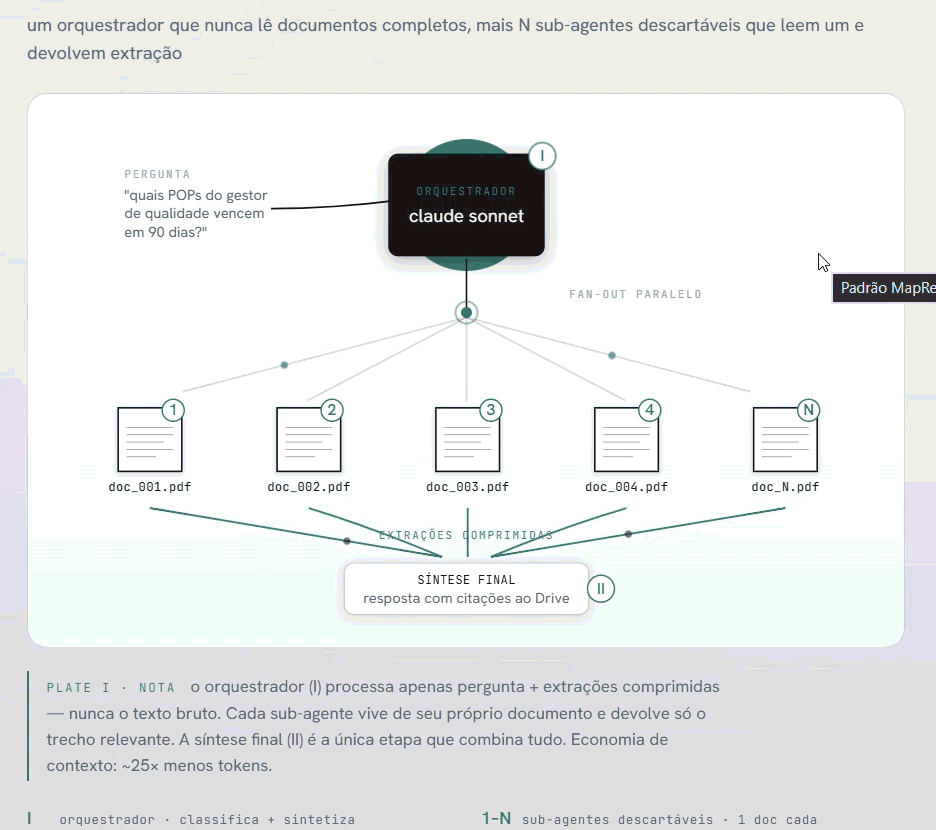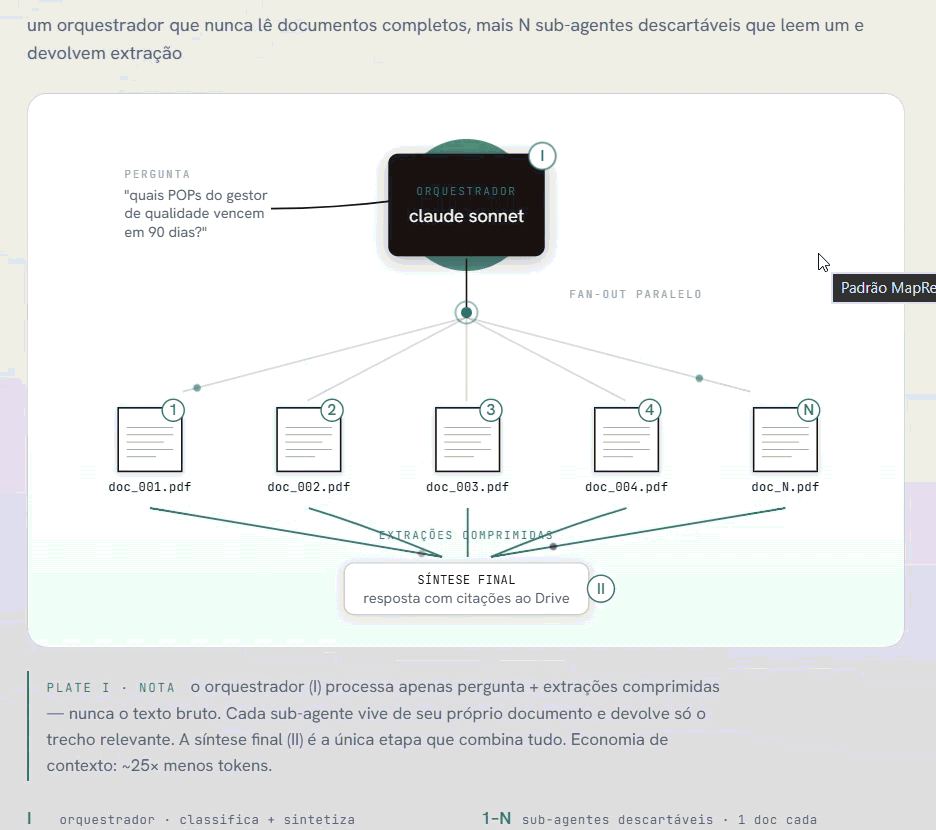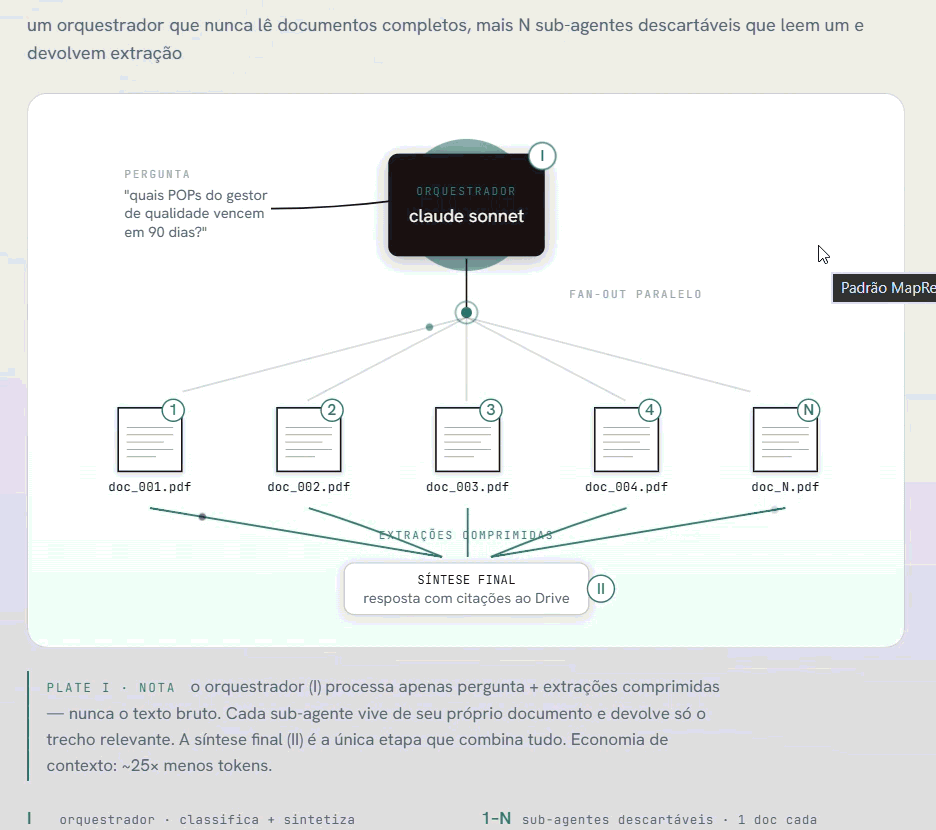
Padrão MapReduce agentico: orquestrador + sub-agentes em paralelo
O orquestrador recebe a pergunta do usuário, decide quais documentos merecem leitura completa, e passa cada um para um sub-agente separado. Cada sub-agente tem contexto limpo: um documento, uma pergunta. Ele devolve só o trecho relevante — não o PDF inteiro. O orquestrador combina as extrações e sintetiza a resposta.
O resultado prático: o orquestrador processa ~25× menos tokens do que processaria se recebesse os documentos completos. A janela de contexto permanece livre para raciocínio — não entupida de texto bruto.
O pipeline em 6 nós
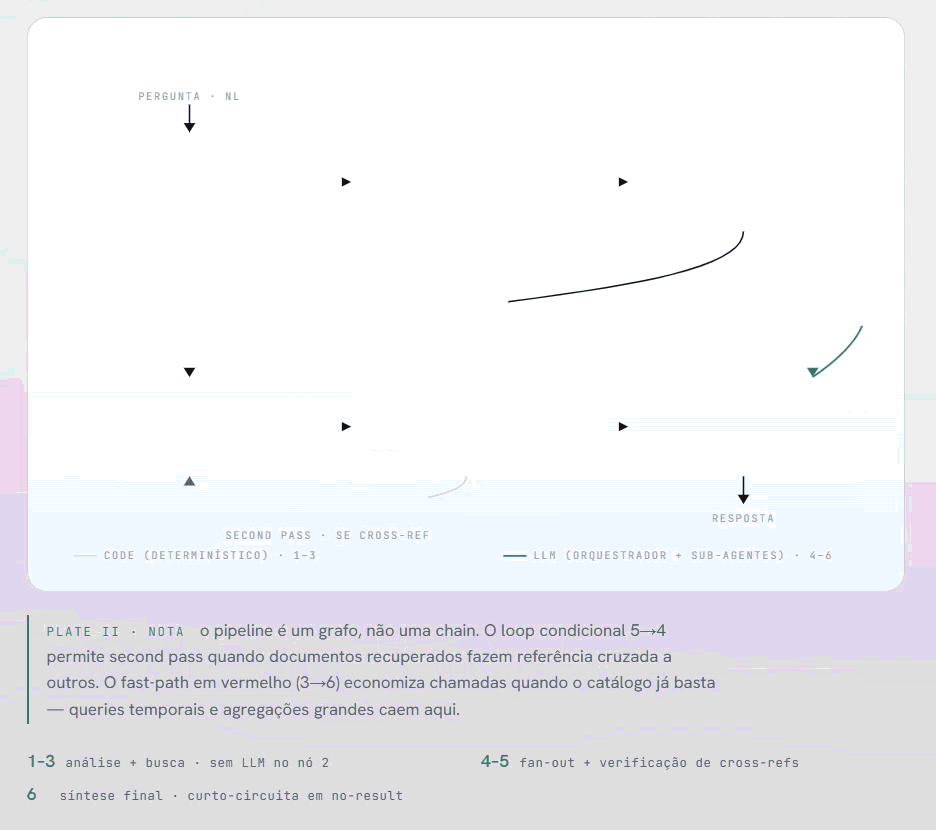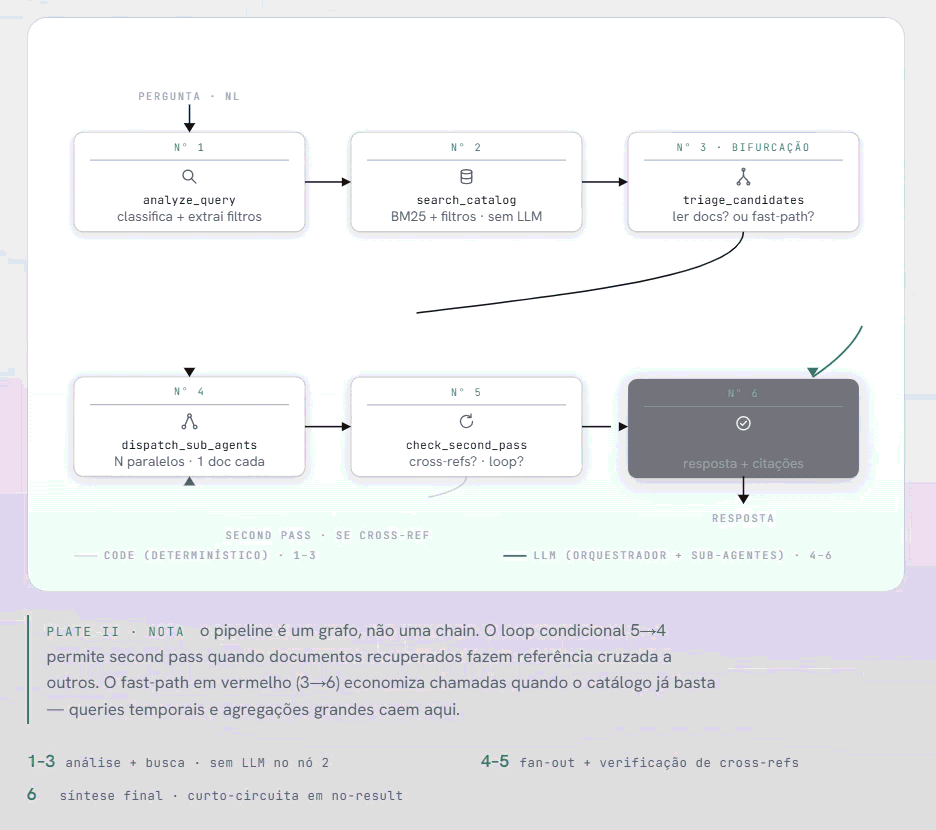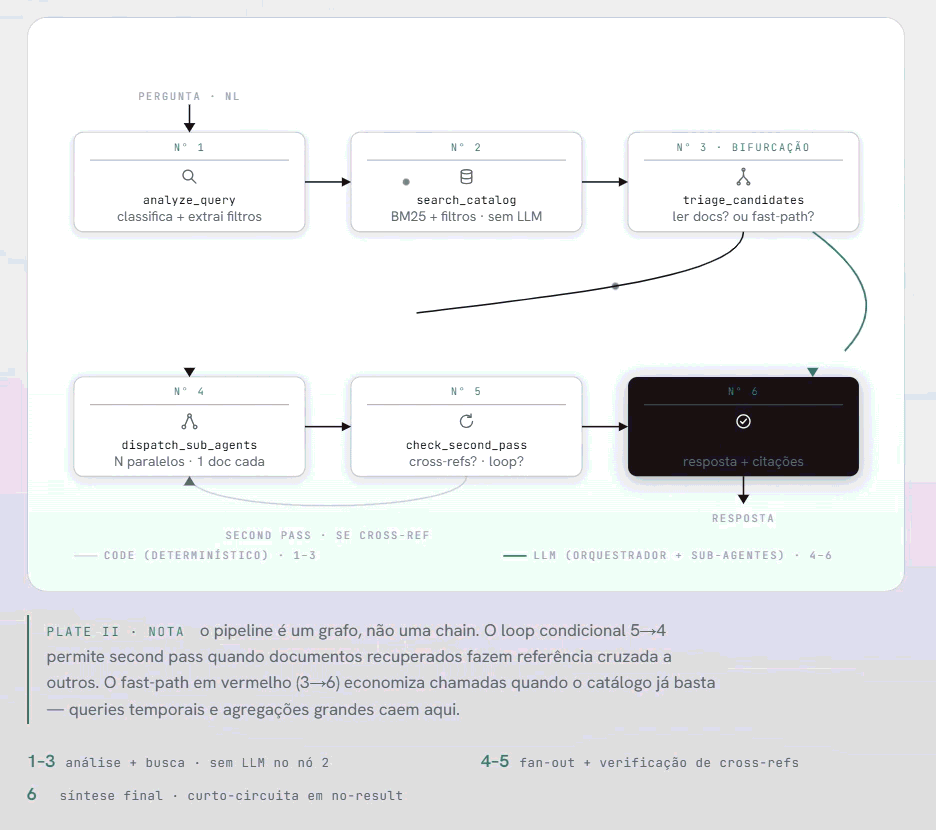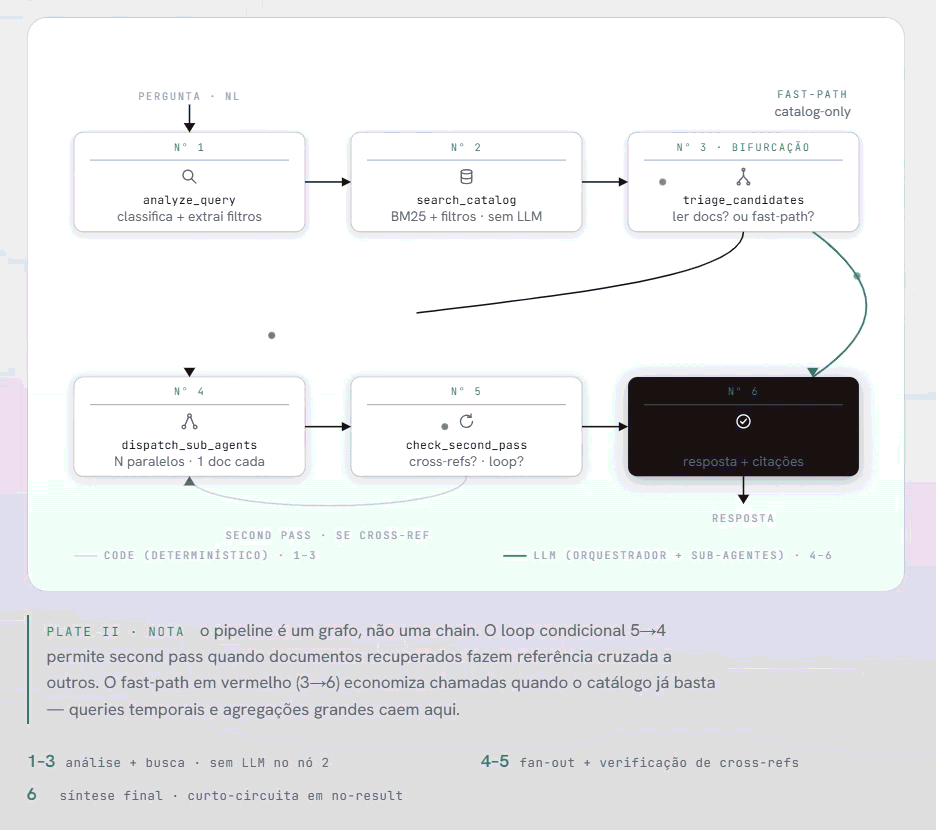
Pipeline LangGraph: 6 nós com second pass e fast-path
O pipeline tem seis nós. A sequência importa tanto quanto os nós em si.
analyze_query é onde o Claude Sonnet recebe a pergunta crua e decide o que fazer com ela. Ele classifica o tipo de query entre cinco categorias — simple, aggregation, comparison, exploratory, temporal — e extrai os filtros estruturados que estão implícitos na linguagem natural. "Documentos sob responsabilidade do gestor de qualidade vencendo em 90 dias" vira { temporal_filter: "expiring_soon", responsible_filter: "gestor de qualidade", doc_type_filter: null }.
search_catalog aplica esses filtros ao catálogo JSONL e roda BM25 sobre o conjunto resultante. Nenhuma chamada de LLM aqui — é código determinístico. Edge case relevante: quando a query é puramente por metadados (sem palavras-chave de conteúdo), o BM25 com query vazia retorna scores aleatórios. O nó detecta isso e faz scan completo com filtros aplicados e score uniforme. Correto e determinístico.
triage_candidates é o nó de bifurcação. O LLM avalia os candidatos retornados pelo BM25 e decide: vale a pena ler os documentos completos, ou o catálogo já tem informação suficiente para responder? Para queries temporais e agregações com mais de oito documentos, o fast-path é acionado — pulamos a leitura de documentos e respondemos direto dos metadados.
dispatch_sub_agents despacha os sub-agentes em paralelo. Cada um recebe o texto de um documento mais a pergunta original mais o contexto de metadados. Devolve uma extração comprimida com relevância classificada. O orquestrador nunca vê o documento completo.
check_second_pass verifica se os documentos recuperados fazem referência cruzada a outros documentos que não estavam no resultado inicial. Se sim, o pipeline volta ao nó 4 para uma segunda rodada. Um loop condicional no grafo LangGraph — por isso o pipeline é um grafo, não uma chain linear.
synthesize_answer combina as extrações, filtra as de baixa relevância, e constrói a resposta final com citações e links diretos aos PDFs no Drive. Um detalhe de implementação que vale mencionar: quando o conjunto de extrações retorna vazio ou com relevância nula, o pipeline curto-circuita sem chamar o LLM. A mensagem de "não encontrado" é construída no código, não gerada por modelo. Mais barato, mais consistente.
A camada de metadados: onde o valor real mora
A extração de responsible e approver merece parágrafo próprio porque foi o ponto de maior resistência técnica.
O rodapé canônico dos documentos da instituição é uma tabela de três colunas: "ELABORADO POR", "VERIFICADO POR", "PUBLICADO POR". Cada coluna tem nome e setor do responsável. O problema é que, extraído do PDF via PyMuPDF, esse texto vira uma sequência linear sem estrutura de coluna — e colunas adjacentes vazam umas nas outras.
A estratégia foi: regex com lookahead negativo nos rótulos vizinhos para evitar o bleed entre colunas, aplicado nos primeiros e últimos 3000 caracteres do texto (o rodapé pode aparecer em qualquer página, mas tipicamente é o último). Se o regex falhar em qualquer campo, chama o GPT-4o-mini com um prompt curto pedindo apenas os dois nomes em JSON. O resultado vem com um campo source: "regex"|"llm"|"mixed"|"none" para telemetria.
Na amostra inicial: ~50% de hit em regex. Os 50% restantes eram tipicamente formulários curtos sem rodapé padrão — onde None é o resultado correto, não um erro.
A consequência prática é que queries como "documentos sob responsabilidade do gestor da área de qualidade" funcionam. O filtro responsible_filter é aplicado no catálogo como substring match, e o conjunto de documentos relevantes é retornado sem que o LLM precise inferir autoria a partir do corpo do texto.
O bug que aprendemos a não cometer de novo
Durante o desenvolvimento, encontramos um padrão de defeito que vale documentar porque é sutíl e recorrente em sistemas RAG com filtragem de metadados.
O filtro funcionava. O sistema encontrava os documentos corretos. Mas a resposta sintetizada não mencionava o responsável — mesmo quando o usuário tinha perguntado explicitamente sobre ele. A query narrava corretamente o conjunto para um único documento de uma pessoa específica, mas o prompt de síntese montava o catalog_text sem incluir o campo responsible. O LLM da síntese via o documento, mas não tinha como afirmar "este documento é de responsabilidade de tal pessoa" — porque essa informação não estava no contexto que ele recebeu.
Toda metadata usada como critério de filtro precisa estar presente também no contexto de síntese. Filtro e apresentação são camadas separadas — e precisam ser alinhadas explicitamente.
O fix foi em três pontos: no dispatch_sub_agents para o caminho temporal, no synthesize_from_catalog, e no prompt do sub-agente regular. Um defeito que não aparece em testes de conteúdo comum, só em testes de governança — exatamente as queries que mais importam para o cliente.
O que faríamos diferente
RBAC no pipeline. O sistema atual não tem controle de acesso por usuário. Qualquer funcionário autenticado pode perguntar sobre qualquer documento. Para documentos de gestão de pessoas ou dados sensíveis de áreas específicas, isso precisaria mudar — um nó de filtro por identidade no OrchestratorState antes do dispatch. A ausência de RBAC foi uma decisão consciente de escopo inicial, não uma omissão.
Vocabulário agnóstico de domínio no analyze_query. O prompt atual tem heurísticas para sinônimos do vocabulário clínico e de qualidade. Se o sistema for estendido para outros setores com vocabulário muito diferente — recursos humanos, jurídico, financeiro — esses prompts vão precisar de revisão ou de variantes por domínio. Não é trabalho trivial.
Limitação do sync incremental. A sincronização com o Drive usa a Changes API, que detecta arquivos novos, modificados ou deletados. Ela não consegue rederive o doc_type da estrutura de pastas — a API entrega apenas metadata do arquivo. Se um documento for movido de uma pasta de tipo A para uma pasta de tipo B, o sync não detecta a mudança de tipo. Um rebuild completo do índice é necessário nesses casos. É uma limitação conhecida que vale monitorar em corpora com reorganizações frequentes.
Como replicar para seu próprio corpus
Se você tem um corpus de documentos internos numa organização com as mesmas características — títulos descritivos, estrutura de pastas com convenção, metadados em cabeçalho e rodapé, atualização contínua — este checklist cobre os passos:
1. Auditar o corpus antes de qualquer código. Olhe para 50 documentos aleatórios. Os títulos já resumem o conteúdo? Os cabeçalhos têm datas de vencimento? Os rodapés têm responsáveis? Se sim, um catálogo estruturado vai performar melhor do que embeddings para a maioria das queries.
2. Mapear a taxonomia antes de tocar na indexação.
Percorra a estrutura de pastas e liste todas as variantes de nomes por tipo de documento (incluindo typos — eles existem em toda organização). Defina TAXONOMY_PREFIXES antes de escrever uma linha de código de indexação. Ordene específico antes de genérico.
3. Usar modelo barato na indexação, modelo bom na resposta. Indexação é um processo batch que tolera erro pontual. GPT-4o-mini para gerar summary, tags e entidades custa ~10× menos que Sonnet. O orquestrador e os sub-agentes, que interagem diretamente com o usuário, merecem o modelo melhor.
4. Implementar filtros como espelho dos campos do catálogo.
Para cada campo filtrável do catálogo (doc_type, responsible, temporal), adicione o filtro correspondente no estado do orquestrador. E garanta que o campo chegue serializado nos prompts de síntese — não só no filtro de busca. Este é o erro mais comum.
5. Testar explicitamente queries de governança, não só queries de conteúdo. "O que diz o procedimento X" é a query óbvia. Mas "quais documentos vencem em 60 dias" e "tudo sob responsabilidade de tal gestor" são as queries que valem mais para o cliente. Cubra os dois eixos nos testes.
6. Implementar o fast-path desde o início. Para queries temporais e aggregations com muitos documentos, responder só com metadados é mais rápido, mais barato e frequentemente mais preciso do que enviar sub-agentes para ler documentos. O roteamento é simples — o investimento vale.
7. Curto-circuitar o "não encontrei" no código. Quando o conjunto de extrações está vazio ou abaixo do threshold de relevância, construa a mensagem no código. Não gaste LLM para gerar "desculpe, não encontrei nada relevante". É mais consistente e mais barato.
O princípio que generaliza
O sistema não é sobre RAG. É sobre reconhecer que, para a maioria dos corpora corporativos reais, o valor não está em embeddings mais sofisticados — está em metadados bem modelados e em uma camada de filtros determinísticos antes da recuperação semântica.
Antes de escolher a ferramenta, observe o processo. O corpus que você recebe já tem estrutura. Sua tarefa é expor essa estrutura — não tentar substituí-la com inferência.
Embeddings são úteis quando o conteúdo é o único índice disponível. Quando a organização já mantém taxonomia, responsáveis, datas e tipos de documento — e em toda organização que sobreviveu mais de cinco anos, esses metadados existem — o investimento certo é em recuperá-los de forma confiável e em torná-los consultáveis via linguagem natural.
O resultado prático: um sistema que responde tanto "o que diz o protocolo de gerenciamento de acompanhantes em RM" quanto "quais documentos do gestor de qualidade vencem nos próximos 90 dias" — com a mesma confiabilidade, o mesmo tempo de resposta, e citação direta ao arquivo original.
Qual a diferença entre RAG com vector store e a abordagem com BM25 + catálogo estruturado?
BM25 é uma função de ranking léxica — ela pontua documentos com base na frequência e distribuição dos termos da query. É determinística, sem custo de API, e debuggável. Vector stores usam similaridade de cosseno entre embeddings, o que captura semântica mas não filtros estruturados.
Para corpora com títulos descritivos e metadados ricos (datas, responsáveis, tipos), BM25 sobre catálogo + filtros determinísticos performa igual ou melhor que embeddings na maioria das queries práticas. A exceção é quando a query e o documento usam vocabulário completamente distinto — nesses casos, embeddings têm vantagem. A escolha depende do corpus.
Por que usar dois provedores de LLM (Anthropic e OpenAI) em vez de um só?
A decisão é econômica e de qualidade ao mesmo tempo. Indexação é uma tarefa batch estruturada: gerar summary, extrair tags, identificar entidades. O GPT-4o-mini custa ~10× menos que Claude Sonnet para essa classe de tarefa, e a diferença de qualidade é irrelevante quando o output é um campo JSON com 3 tags.
Orquestração e síntese são diferentes. A análise de query precisa classificar tipo, extrair filtros implícitos, e lidar com ambiguidade em português brasileiro. A síntese final precisa ser fiel ao texto dos documentos e coerente. Aí o Sonnet justifica o custo. A regra geral: modelo barato onde a tarefa é estruturada e batch, modelo bom onde o usuário vai ler o output.
O sistema consegue responder perguntas que exigem leitura de múltiplos documentos ao mesmo tempo?
Sim, via o padrão MapReduce. Sub-agentes leem documentos em paralelo e devolvem extrações comprimidas. O orquestrador recebe apenas os trechos relevantes de cada documento — não os documentos completos — e sintetiza a resposta com base nas extrações.
Isso resolve dois problemas: o limite de janela de contexto (impossível enviar 10 PDFs completos a um LLM e manter qualidade) e o custo (sub-agentes com contexto limpo processam ~25× menos tokens do que um orquestrador que lê tudo). A query "compare o protocolo A com o protocolo B" funciona exatamente assim.
Como funciona a sincronização automática com o Drive?
A Changes API do Google Drive retorna uma lista de arquivos criados, modificados ou deletados desde a última sincronização, identificados por um token persistido localmente. O indexer processa apenas o delta — não rebuilda o catálogo inteiro a cada sync.
A limitação conhecida é que a Changes API entrega apenas metadata do arquivo, não sua posição na árvore de pastas. Se um documento for movido entre pastas de tipos diferentes, o sync não detecta a mudança de doc_type. Nesses casos, um rebuild completo é necessário. É um trade-off aceitável para corpora com reorganizações infrequentes.
O que é o fast-path "catalog-only" e quando ele é acionado?
Para certas classes de query, o catálogo de metadados já contém a resposta completa — sem precisar ler o conteúdo dos documentos. Queries temporais ("quais documentos vencem em 30 dias"), aggregations com muitos documentos ("liste todos os manuais do setor X"), e queries puramente por responsável são os casos típicos.
Nesses casos, o nó triage_candidates aciona o fast-path: o pipeline pula o dispatch_sub_agents e sintetiza a resposta diretamente dos resumos e metadados do catálogo. É mais rápido (sem I/O de leitura de PDF), mais barato (sem chamadas de sub-agente), e frequentemente mais preciso (o catálogo tem exatamente os campos que a query precisa, sem ruído de conteúdo).