Em radiologia, o slot de exame vazio não é só uma vaga perdida — é uma hora de equipamento de sete dígitos parado enquanto a fila de espera não se move.
Uma vaga vazia custa mais do que parece
Em radiologia de alta complexidade, o custo marginal de um slot de exame é diferente de quase todo o resto da medicina. Uma consulta desperdiçada custa o tempo do médico. Um slot de ressonância magnética desperdiçado custa o tempo do médico — mais a depreciação horária de um equipamento que pode valer dezenas de milhões de reais, mais o ar-condicionado específico, mais o técnico escalado. A hora-equipamento não volta. E enquanto o slot fica vazio, há uma fila de pacientes aguardando semanas para um exame que poderia ter sido realizado hoje.
O instituto de radiologia de um grande complexo hospitalar público com quem trabalhamos enfrentava esse problema em escala. A taxa de no-show era de aproximadamente 26% — cerca de 150 mil faltas por ano. Em capacidade ociosa e receita não realizada, esse número representa mais de R$ 10 milhões anuais. Um em cada quatro agendamentos não comparecia, e a instituição não tinha nenhuma estratégia sistemática para prever ou compensar esse padrão. O que existia era reativo: quando um paciente faltava, a equipe de agendamento tentava preencher o slot com pacientes internados de última hora. Funcionava às vezes. Na maioria das vezes, o equipamento ficava parado.
Este case descreve o projeto de modelagem preditiva que construímos para transformar esse padrão em algo antecipável. Não descrevemos um sistema em produção — descrevemos um modelo treinado, validado com rigor, e uma proposta de piloto que aguarda aprovação executiva. Separar o que é real do que é projeção não é uma ressalva protocolar. É o que torna um case crível.
O que a análise descritiva revelou antes de qualquer modelo
Antes de treinar qualquer algoritmo, passamos semanas num trabalho que raramente ganha destaque em posts técnicos, mas que determinou mais do que qualquer escolha de hiperparâmetro: análise exploratória profunda e decomposição de séries temporais.
A análise descritiva produziu mais de 20 visualizações analíticas que mapearam o comportamento de falta em cada dimensão disponível. Os padrões que emergiram eram reveladores.
Por modalidade: a taxa de no-show variava de forma significativa. Raio-X apresentava cerca de 8% de absenteísmo — o mais baixo do portfólio. Tomografia ficava em torno de 12%. Ressonância magnética chegava a 15%, exatamente o tipo de exame onde o custo da ociosidade é mais alto. A diferença não é aleatória: ressonâncias são agendadas com maior antecedência, custam mais ao paciente em termos de tempo e deslocamento, e têm substituição mais difícil se o slot for desperdiçado.
Por padrão temporal: a decomposição com SARIMAX revelou sazonalidade estrutural — segundas-feiras concentravam taxas de absenteísmo em torno de 26%, acima da média. Mais surpreendente: slots em horários extremos de fim de semana, como o intervalo das 20h às 22h, apresentavam taxas chegando a 90–100% de no-show. Esses slots existiam no sistema, eram agendados, e quase nunca eram cumpridos. Era um problema de configuração de grade que a análise descritiva tornou visível antes de o modelo chegar.
Essa fase de análise não foi preliminar no sentido de descartável. Ela gerou hipóteses que guiaram a engenharia de features, e revelou um fato que se tornaria central na interpretação do modelo: o comportamento de falta tem estrutura, e parte dessa estrutura é explicável sem machine learning.
O herói esquecido: data engineering
Se há uma lição que este projeto reforça com mais força do que qualquer outra, é que em ML aplicado a dados de saúde, o valor mora na camada de dados, não no algoritmo.
Os dados existiam. O data warehouse colunar da instituição tinha anos de histórico de agendamentos, exames realizados, cancelamentos, perfis de pacientes, modalidades, convênios. O dado estava lá. O problema era que estava fragmentado, inconsistente, e distribuído em múltiplas fontes com diferentes convenções de nomenclatura, critérios de categorização, e granularidade.
Construir o dataset mestre que alimentaria o modelo exigiu um trabalho de engenharia que consumiu mais tempo do que o treinamento, a validação e a análise combinados. As etapas principais foram:
Normalização de categorias: convênios registrados com variações de grafia para o mesmo pagador. Modalidades com codificações distintas em sistemas diferentes. CIDs com versões mistas. Cada inconsistência que não fosse corrigida produziria features ruidosas que degradariam o modelo.
Definição precisa do target: este passo parece trivial e não é. No-show, para os propósitos deste modelo, significa falta sem cancelamento prévio. Um paciente que liga no dia anterior e cancela não é um no-show — é um cancelamento. A distinção importa: cancelamentos dão tempo para reagendamento; no-shows não dão. O modelo foi treinado especificamente para prever o comportamento que a instituição não tem como compensar. Misturar cancelamentos com no-shows produziria um modelo que acerta o rótulo errado.
Integração de fontes: juntar agendamentos com histórico do paciente, modalidade do exame, convênio, e contexto temporal exigiu múltiplos JOINs entre views diferentes com chaves de integração que nem sempre estavam documentadas. Entender a estrutura do data warehouse — qual fonte era autoritativa para cada campo, onde havia conflitos entre sistemas — foi o trabalho de engenharia que mais dependeu de conhecimento institucional.
Em ML preditivo na saúde, a qualidade do modelo é limitada pela qualidade do dataset. Um engenheiro que passa 80% do tempo em data engineering e 20% em modelagem entrega resultados melhores do que o inverso.
O dataset final consolidou aproximadamente 510 mil registros de exames cobrindo três anos de operação, com 13 features engenheiradas e um target binário limpo.
As features que o modelo aprendeu — e a que dominou tudo
Com o dataset mestre construído, o processo de seleção e engenharia de features foi guiado tanto pela análise descritiva prévia quanto pela intuição sobre o que, numa operação de agendamento, é observável no momento da marcação.
As famílias de features consideradas foram:
- Comportamentais: histórico de no-show do paciente (número de faltas anteriores, taxa histórica de comparecimento), número de agendamentos anteriores, frequência de uso do serviço
- Temporais: lead-time entre data de marcação e data do exame, dia da semana do exame, horário do exame, mês
- Clínicas: modalidade do exame, CID-10 registrado, prioridade clínica
- Demográficas e contratuais: faixa etária, sexo, tipo de convênio
O preditor mais forte, de longe, foi o histórico comportamental do paciente.
A análise de segmentação por perfil de frequência tornou isso explícito. Pacientes classificados como "frequentes" — com histórico de múltiplas faltas — apresentavam taxa de no-show em torno de 50%. Pacientes sem nenhuma falta registrada ficavam em torno de 15%. A distância entre esses grupos é enorme. O que o dado está dizendo é o que qualquer gestor experiente de agendamento sabe intuitivamente mas raramente consegue quantificar: quem faltou antes provavelmente falta de novo.
O lead-time também teve poder preditivo relevante. Agendamentos com antecedência muito longa — acima de 60 dias — concentravam proporcionalmente mais faltas. A hipótese é comportamental: quanto mais distante o compromisso, maior a probabilidade de mudanças de circunstância que o paciente não comunicará antecipadamente.
O modelo não descobriu nada que um agendador experiente não soubesse. Ele transformou esse conhecimento tácito em um score individual, replicável para 150 mil agendamentos por ano, sem depender da memória ou do turno de nenhuma pessoa específica.
A escolha do algoritmo e a validação que importa
O algoritmo final foi CatBoost — não XGBoost, que serviu como linha de base durante o desenvolvimento. A diferença prática entre os dois neste problema foi marginal; o que CatBoost resolveu de forma mais elegante foi o tratamento nativo de variáveis categóricas sem encoding manual extensivo, o que simplificou o pipeline e reduziu o risco de leakage por transformação inadequada de categorias de alta cardinalidade, como convênio e CID.
A escolha do algoritmo, no entanto, foi a decisão menos importante do projeto. Isso não é modéstia — é o que os dados mostram. A diferença de AUC entre os principais algoritmos testados (CatBoost, XGBoost, Random Forest, Regressão Logística como baseline) foi menor do que a diferença produzida por uma feature de histórico do paciente bem construída.
O que importou mais do que o algoritmo foi a estratégia de validação.
Dados de agendamento têm sazonalidade estrutural. Se você divide o dataset aleatoriamente em treino e teste, você inevitavelmente usa informação do futuro para treinar — um paciente que faltou em março aparece no treino, e o mesmo padrão de comportamento está no teste de janeiro. O modelo aprende a "lembrar" de padrões que, na produção real, ainda não teriam acontecido. O resultado é um AUC inflado que despenca quando o modelo encontra dados reais prospectivos.
A validação que adotamos foi temporal: treino no histórico até um corte definido, teste nos 6 meses seguintes em ordem cronológica. O modelo nunca viu dados do futuro durante o treino. Essa é a única validação que imita o que aconteceria em produção.
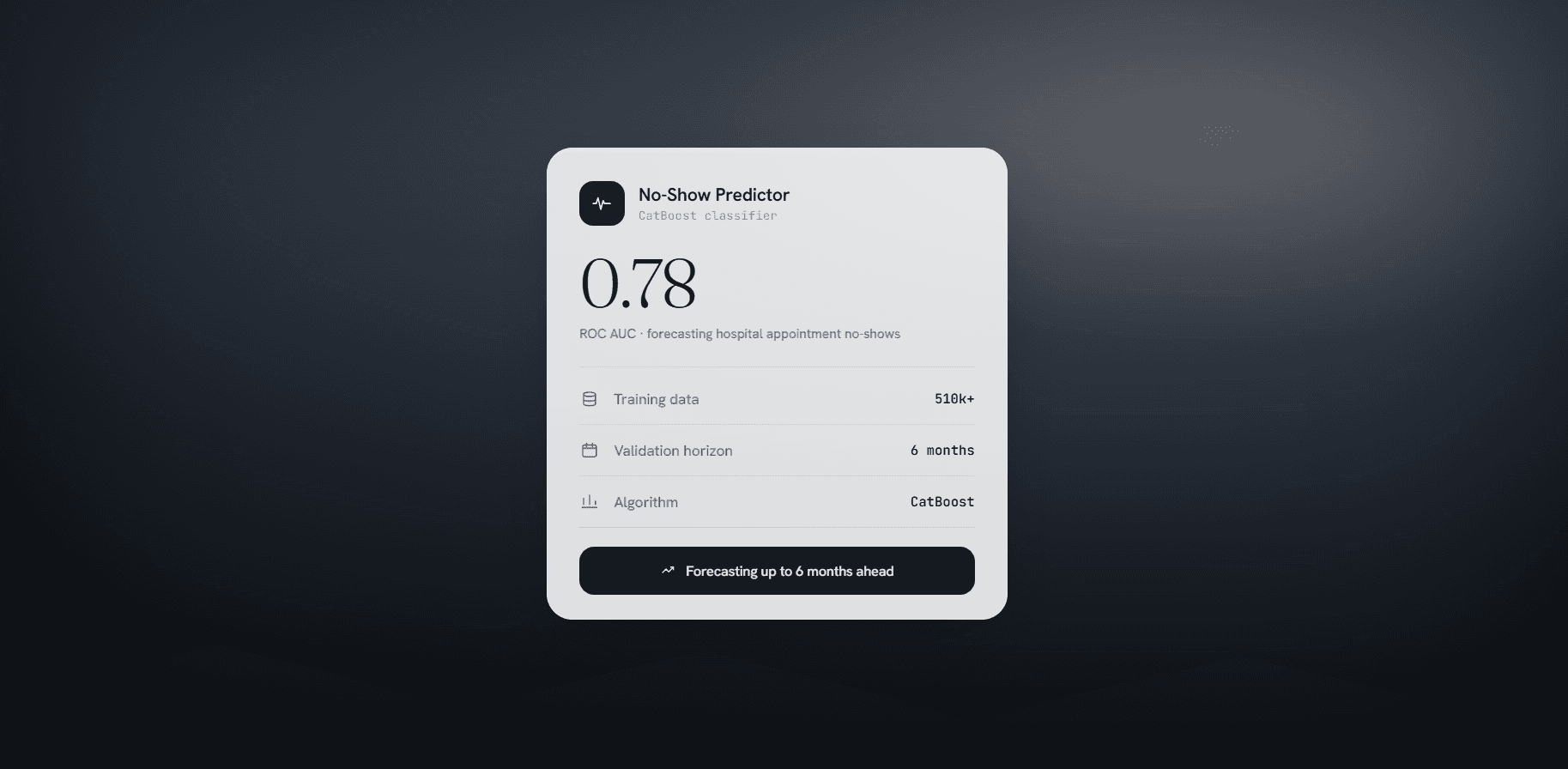
O ROC-AUC resultante foi 0,78 no teste temporal. Não é o número mais alto que este dataset consegue produzir — com validação aleatória, chegamos a valores mais elevados. É, no entanto, o número que representa o desempenho real esperado quando o modelo for usado de forma prospectiva.
A comparação com a literatura mundial ilustra por que esse rigor importa.
Onde este modelo se posiciona na literatura global
O benchmarking contra estudos publicados foi parte do escopo deste projeto, e os resultados são honestos o suficiente para ser contados sem seleção favorável.
Comparamos o modelo com estudos de predição de no-show em radiologia e outras especialidades de grandes instituições — centros nos EUA (Massachusetts General Hospital, Universidade de Maryland), Singapura (Changi General Hospital), Israel (Assuta Medical Centers), Japão. A maioria dos estudos publicados usa validação aleatória ou cross-validation temporal menos rigorosa.
O padrão que encontramos repetidamente: modelos que reportam AUC de 0,90 ou mais em teste, mas caem para 0,73–0,74 quando revalidados com dados prospectivos reais. Um estudo específico publicou AUC de 0,93 em validação cruzada e 0,73 em teste prospectivo — uma queda de 20 pontos que só aparece quando a metodologia é honesta com o tempo.
Nosso modelo, treinado e validado sob o protocolo mais restritivo, entrega 0,78 no teste prospectivo. Isso o posiciona acima de aproximadamente 75% dos estudos comparáveis em performance prospectiva real — não em performance de benchmark otimista.
Os diferenciais que tornam a comparação válida: o dataset cobre 15 ou mais modalidades diferentes num único modelo (a maioria dos estudos é uni-modal), e o volume de 510 mil registros supera a maior parte dos datasets publicados em cenários de saúde pública.
O que o piloto propõe — e o que ainda não aconteceu
O modelo existe. A validação existe. O que não existe ainda é um sistema em produção.
A proposta de piloto — que aguarda aprovação executiva — é estruturada em torno de um mecanismo de overbooking inteligente fundamentalmente diferente do overbooking grosseiro que algumas instituições praticam.
A lógica é simples: o modelo gera um score de probabilidade de falta para cada agendamento no momento da marcação. Quando esse score ultrapassa um limiar de aproximadamente 70%, o sistema sugere ao agendador que o slot pode receber um agendamento adicional. O agendador valida. A sugestão não é automática — é suporte à decisão com base estatística.
Os mecanismos de segurança propostos são igualmente importantes quanto a sugestão em si:
- Teto de overbooking por modalidade: máximo de 10–15% de slots adicionais por sessão, para evitar superlotação se o modelo subestimar comparecimento
- Stop rules automáticas: se o overfill real em qualquer sessão exceder 5%, ou se o tempo de espera subir mais de 30 minutos acima do SLA, o overbooking é suspenso automaticamente naquele dia
- Exceções clínicas rígidas: pacientes com exames de alta complexidade ou classificados como urgentes são 100% excluídos de qualquer lógica de overbooking, independentemente do score
A filosofia que guia o design é "fail-safe": em qualquer condição de incerteza, o sistema reverte ao comportamento padrão. Zero prejuízo ao paciente como consequência de uma predição incorreta do modelo.
As projeções de impacto — recuperação de 10–15% da ociosidade atual, representando entre R$ 1,5M e R$ 2,5M anuais em capacidade adicional utilizada — são estimativas construídas sobre a performance do modelo e premissas conservadoras de aderência operacional. São cenários para um piloto de 90 dias, não resultados observados. A distância entre um modelo validado e um sistema em produção é real, e preencher essa distância com honestidade é parte do projeto.
O modelo foi projetado como blueprint replicável para outros institutos do mesmo complexo hospitalar — que enfrentam variações do mesmo problema com o mesmo tipo de dado disponível.
Como replicar essa arquitetura
Se você está construindo um modelo preditivo de no-show para uma operação hospitalar, estas são as decisões que mais importam, em ordem de impacto real:
1. Defina o target antes de tocar nos dados. No-show não é sinônimo de "não compareceu". Cancelamentos antecipados, remarcações, faltas por internação — cada um tem semântica diferente e merece tratamento diferente. Defina o rótulo que o modelo precisa prever antes de construir o dataset. Uma definição imprecisa aqui contamina tudo que vem depois.
2. Invista a maior parte do tempo em data engineering. A regra prática que emergiu deste projeto: se você está gastando menos de 50% do esforço em limpeza, normalização e integração de fontes, provavelmente está subestimando o problema. Features ruidosas produzem modelos ruidosos, independentemente do algoritmo.
3. Use validação temporal, não aleatória. Se os dados têm sazonalidade — e dados de agendamento hospitalar têm —, validação aleatória produz métricas que não correspondem à realidade prospectiva. Treine no passado, teste no futuro. Aceite a possível queda no AUC como informação, não como fracasso.
4. Priorize features comportamentais do paciente. O histórico de no-show do paciente é, consistentemente, o preditor mais forte neste domínio. Antes de investir em features clínicas sofisticadas ou em engenharia temporal elaborada, certifique-se de que o histórico do paciente está bem representado e limpo no dataset.
5. Faça a análise descritiva antes do modelo. A decomposição temporal (SARIMAX ou equivalente) e as análises de segmentação revelam padrões que informam a engenharia de features e evitam que o modelo precise "descobrir" o que o dado já mostra claramente. Slots das 20h às 22h no fim de semana com 90% de no-show são um problema de configuração de grade, não de predição.
6. Projete o mecanismo de aplicação com soberania humana. Em sistemas que afetam diretamente o cuidado ao paciente, automação cega é o risco errado a tomar. O modelo é um instrumento de suporte à decisão — ele informa o agendador, não substitui o julgamento. Construa os mecanismos de override, as stop rules e as exceções clínicas antes de pensar em deploy.
O que faríamos diferente
A normalização de categorias foi feita de forma incremental ao longo do projeto, corrigindo inconsistências à medida que elas apareciam na análise. O processo correto seria construir um dicionário canônico de cada variável categórica — convênios, modalidades, CIDs relevantes — antes de iniciar a limpeza. Isso teria economizado múltiplas iterações de reprocessamento do dataset.
O benchmarking contra a literatura foi feito de forma relativamente manual — leitura de papers, extração de métricas, comparação em planilha. Para um projeto onde a comparação com estudos publicados é parte do argumento de valor, um pipeline de benchmarking mais sistemático teria sido útil: uma base estruturada de estudos com métricas padronizadas, condições de validação documentadas, e comparação automatizada.
A análise de custo de erro por tipo (falso positivo vs. falso negativo no contexto de overbooking) poderia ter sido formalizada mais cedo. O AUC é uma métrica útil de discriminação, mas a decisão de threshold para a sugestão de overbooking depende da assimetria de custo específica da operação — custo de um slot sugerido erroneamente (paciente que comparece, sala cheia) versus custo de um slot subutilizado (falta que não foi prevista). Essa análise veio tarde no projeto.
O princípio que conecta este projeto ao ecossistema de dados
Este projeto de predição de no-show e o agente de dados que construímos para a mesma instituição partem do mesmo ponto — um data warehouse colunar vasto, desorganizado, e subutilizado — e chegam a lugares diferentes por caminhos diferentes.
O agente de dados é reativo: um gestor faz uma pergunta em linguagem natural, o agente traduz para SQL, executa, interpreta e responde. O valor está na eliminação do gargalo humano entre a pergunta e o dado.
Este modelo de predição é proativo: sem nenhuma pergunta, ele analisa cada novo agendamento e calcula a probabilidade de falta. O valor está em agir antes do evento, não depois.
Os dois projetos transformam o mesmo data warehouse desorganizado em valor operacional. A diferença é temporal: um responde ao presente, o outro antecipa o futuro. O que os une é a convicção de que dados existentes, bem trabalhados, têm mais valor do que qualquer dado novo que se poderia coletar.
O dado já estava lá. O trabalho foi entender o que ele dizia — e construir a camada que tornava possível ouvi-lo de forma sistemática.
Qual a diferença entre no-show e cancelamento neste modelo?
A distinção é central para a utilidade do modelo. No-show, conforme definido neste projeto, é a falta sem cancelamento prévio — o paciente simplesmente não comparece sem comunicar à instituição. Cancelamentos, mesmo de última hora, são registros distintos.
A razão para essa separação é operacional: um cancelamento, mesmo que tardio, dá alguma possibilidade de reaproveitamento do slot. Um no-show não dá. A instituição descobre que o paciente faltou apenas quando o horário começa e o paciente não está lá. Esse é o comportamento que destrói capacidade e que o modelo foi treinado para antecipar.
Misturar os dois rótulos no target produziria um modelo que prevê "ausência por qualquer razão" — útil para outras finalidades, mas não para o mecanismo de overbooking inteligente que este projeto propõe.
Por que CatBoost e não XGBoost ou outro gradient boosting?
XGBoost foi a linha de base do projeto e performou de forma competitiva. A escolha por CatBoost como modelo final foi motivada principalmente pelo tratamento nativo de variáveis categóricas.
O dataset tem features de alta cardinalidade — convênio, CID, modalidade — que com XGBoost exigem encoding explícito (one-hot ou target encoding). Target encoding com validação temporal requer cuidados adicionais para evitar leakage. CatBoost lida com categorias diretamente, sem encoding externo, reduzindo a complexidade do pipeline e o risco de erros de implementação.
A diferença em AUC entre os dois foi pequena — na ordem de 0,01 a 0,02. A escolha foi de engenharia de pipeline, não de performance pura.
Por que a validação temporal é mais importante do que cross-validation padrão neste caso?
Dados de agendamento têm sazonalidade estrutural: padrões de falta variam por dia da semana, mês, período do ano, e eventos externos (feriados, campanhas de saúde, etc.). Quando você faz cross-validation aleatória, o modelo treina em registros de dezembro e testa em registros de janeiro — mas também treina em registros de fevereiro e testa em registros do mesmo fevereiro de anos diferentes. A informação "vaza" temporalmente.
O resultado prático é um AUC inflado que não corresponde ao desempenho prospectivo. Publicamos 0,78 porque esse é o número obtido com o protocolo mais restritivo: treino no passado, teste em 6 meses futuros cronológicos que o modelo nunca viu. É o número que importa para decidir se o modelo é útil em produção.
A literatura global mostra esse padrão repetidamente: modelos que reportam AUC de 0,90+ com validação cruzada caem para 0,73–0,74 quando testados prospectivamente. A honestidade metodológica é parte do resultado.
O mecanismo de overbooking não corre o risco de prejudicar pacientes?
Esse é o risco central de design, e a proposta de piloto foi construída para endereçá-lo explicitamente.
Três salvaguardas estruturais foram projetadas. Primeiro, o threshold de sugestão é conservador: apenas slots onde o score de probabilidade de falta supera 70% recebem sugestão de overbooking. Isso filtra a maioria dos agendamentos. Segundo, o teto por sessão limita o overbooking a 10–15% dos slots — se o modelo subestimar o comparecimento em um dia específico, o excesso é absorvível operacionalmente. Terceiro, as stop rules automáticas suspendem o overbooking se os indicadores de lotação real excederem os limiares definidos.
Além disso, a sugestão nunca é automática. O agendador vê o score e decide. E pacientes com exames de alta complexidade ou urgentes são excluídos independentemente do score.
O princípio que governa o design é "fail-safe": em qualquer condição de dúvida, o sistema reverte ao comportamento padrão. O modelo pode errar — a estrutura operacional garante que o erro do modelo não se traduza em prejuízo ao paciente.
Como o histórico comportamental do paciente é calculado sem violar privacidade?
O histórico comportamental é calculado a partir dos próprios registros de agendamento da instituição — dados que ela já possui e já usa operacionalmente. Não envolve coleta de dados externos, cruzamento com bases de terceiros, ou qualquer informação além do que já está no sistema de agendamento.
As features derivadas desse histórico são agregações numéricas: número de agendamentos anteriores, número de faltas anteriores, taxa histórica de comparecimento. Nenhum registro individual de falta é exposto ao modelo como feature — apenas agregações que descrevem o padrão geral do paciente.
O modelo processa esses dados no ambiente interno da instituição. Nenhuma informação de paciente trafega para sistemas externos.